6 Od Próby do Populacji - Zrozumienie Losowości, Pobierania Próby i Wnioskowania
Metody Doboru Próby
Dobór Probabilistyczny (Losowy)
Metody doboru probabilistycznego opierają się na losowym doborze, gdzie każdy członek populacji ma znaną, niezerową szansę na wybór. Metody te pozwalają badaczom obliczyć błąd próby i wyciągać wnioski statystyczne o populacji.
- Prosty Dobór Losowy (SRS)
- Definicja: Każdy członek populacji ma równą szansę na wybór.
- Zalety: Minimalizuje błąd selekcji; umożliwia prostą analizę statystyczną.
- Wady: Wymaga kompletnej operatu losowania; może nie uchwycić wystarczającej liczby członków mniejszych podgrup.
- Przykład: Aby wybrać 100 studentów z uniwersytetu liczącego 10 000 studentów, przypisz każdemu studentowi numer i użyj generatora liczb losowych do wybrania 100 numerów.
- Najlepsze zastosowanie: Gdy populacja jest względnie jednorodna i dostępna jest kompletna lista członków populacji.
- Dobór Losowy Warstwowy
- Definicja: Populacja jest podzielona na wzajemnie wykluczające się podgrupy (warstwy) na podstawie wspólnych cech, a następnie próbki są losowo wybierane z każdej warstwy.
- Zalety: Zapewnia reprezentację kluczowych podgrup; może poprawić precyzję dla tej samej wielkości próby co SRS; umożliwia analizę wewnątrz i między warstwami.
- Wady: Wymaga wcześniejszej znajomości cech populacji do stratyfikacji; bardziej złożona analiza.
- Przykład: W krajowym sondażu politycznym, podziel populację na warstwy według regionów geograficznych (Północny-Wschód, Północny-Zachód, Południe, itp.) i następnie losowo pobierz próbki z każdego regionu proporcjonalnie do ich wielkości populacji.
- Najlepsze zastosowanie: Gdy populacja zawiera wyraźne podgrupy, które mogą reagować różnie na pytanie badawcze.
- Dobór Grupowy (Klastrowy)
- Definicja: Populacja jest podzielona na grupy (zwykle geograficzne), niektóre grupy są losowo wybierane, a wszyscy członkowie w tych grupach są badani.
- Zalety: Bardziej opłacalny gdy populacja jest geograficznie rozproszona; nie wymaga kompletnej listy członków populacji.
- Wady: Niższa precyzja statystyczna niż SRS lub dobór warstwowy; klastry muszą być reprezentatywne.
- Przykład: Aby zbadać nawyki uczenia się uczniów szkół średnich, losowo wybierz 20 szkół średnich z całego kraju i zbadaj wszystkich uczniów w tych szkołach.
- Najlepsze zastosowanie: Gdy populacja jest szeroko rozproszona geograficznie, a dotarcie do wszystkich jednostek byłoby kosztowne.
- Dobór Systematyczny
- Definicja: Wybieranie co k-tego elementu z listy po losowym starcie.
- Zalety: Prosty w implementacji; często bardziej praktyczny niż SRS; może uniknąć efektów sąsiedztwa.
- Wady: Może wprowadzić błąd, jeśli w liście występuje okresowy wzorzec.
- Przykład: W zatłoczonym centrum handlowym, badaj co 20. osobę, która wchodzi, zaczynając od losowo wybranego numeru między 1 a 20.
- Najlepsze zastosowanie: Gdy populacja jest uporządkowana losowo lub w sposób niezwiązany ze zmiennymi badania.
- Dobór Wielostopniowy
- Definicja: Łączenie wielu metod próbkowania w etapach.
- Zalety: Praktyczny dla badań na dużą skalę; równoważy koszty i precyzję.
- Wady: Złożony projekt i analiza; wiele etapów może kumulować błędy próbkowania.
- Przykład: Najpierw losowo wybierz powiaty (dobór klastrowy), następnie losowo wybierz gospodarstwa domowe w tych powiatach (prosty dobór losowy), a na końcu wybierz jednego dorosłego z każdego gospodarstwa (dobór systematyczny).
- Najlepsze zastosowanie: Badanie dużych, złożonych populacji na rozległych obszarach geograficznych.
Dobór Nieprobabilistyczny (Nielosowy)
Dobór nieprobabilistyczny nie opiera się na losowym wyborze, co oznacza, że wnioskowanie statystyczne o populacji musi być dokonywane z ostrożnością. Chociaż może wprowadzać błąd, w niektórych sytuacjach jest niezbędny.
- Dobór Przypadkowy (Convenience Sampling)
- Definicja: Wybieranie łatwo dostępnych podmiotów.
- Zalety: Szybki, niedrogi i łatwy w implementacji.
- Wady: Wysokie ryzyko błędu selekcji; ograniczona możliwość uogólniania.
- Przykład: Badacz studiujący wzorce snu studentów może ankietować studentów ze swoich własnych zajęć.
- Najlepsze zastosowanie: Badania pilotażowe, badania eksploracyjne lub gdy zasoby są znacznie ograniczone.
- Dobór Celowy
- Definicja: Wybieranie podmiotów na podstawie określonych cech istotnych dla pytania badawczego.
- Zalety: Koncentruje się na istotnych przypadkach; przydatny do dogłębnych badań określonych grup.
- Wady: Błąd badacza w wyborze; ograniczona możliwość uogólniania.
- Przykład: W badaniu doświadczeń dyrektorów generalnych w branży technologicznej, celowo poszukuj i przeprowadzaj wywiady z dyrektorami różnych firm technologicznych.
- Najlepsze zastosowanie: Badania jakościowe, studia przypadków lub badanie unikalnych populacji.
- Dobór Kuli Śnieżnej
- Definicja: Uczestnicy rekrutują innych uczestników ze swoich sieci.
- Zalety: Dostęp do trudno dostępnych lub ukrytych populacji; bazuje na sieciach społecznych.
- Wady: Próba stronnicza w kierunku osób w określonych sieciach społecznych; nie można obliczyć prawdopodobieństwa wyboru.
- Przykład: W badaniu dostępu nielegalnych imigrantów do opieki zdrowotnej, badacze proszą początkowych uczestników o polecenie innych potencjalnych uczestników.
- Najlepsze zastosowanie: Badanie rzadkich populacji lub wrażliwych tematów, gdzie nie istnieje operat losowania.
- Dobór Kwotowy
- Definicja: Wybieranie uczestników w celu spełnienia określonych kwot dla pewnych cech, aby dopasować do znanych parametrów populacji.
- Zalety: Zapewnia reprezentację kluczowych grup demograficznych; szybszy i tańszy niż próbkowanie probabilistyczne; nie wymaga operatu losowania.
- Wady: Nielosowy wybór w ramach kwot może wprowadzić błąd; wnioskowanie jest ograniczone.
- Przykład: W badaniu rynkowym, badacze upewniają się, że przeprowadzają wywiady z określoną liczbą osób z różnych grup wiekowych, płci i poziomów dochodów.
- Najlepsze zastosowanie: Komercyjne sondaże, badania rynkowe lub gdy próbkowanie probabilistyczne nie jest wykonalne.
Próby Kwotowe vs. Próby Warstwowe: Porównanie i Praktyczne Zastosowania
Choć na pierwszy rzut oka próbkowanie warstwowe i kwotowe może wydawać się podobne, istnieją między nimi fundamentalne różnice:
Kluczowe różnice między doborem warstwowym a kwotowym:
- Podstawa metodologiczna:
- Dobór warstwowy: Jest metodą probabilistyczną, gdzie po podziale na warstwy, jednostki w każdej warstwie są wybierane losowo.
- Dobór kwotowy: Jest metodą nieprobabilistyczną, gdzie badacz lub ankieter ma swobodę wyboru konkretnych jednostek, o ile spełnione są założone kwoty.
- Możliwość wnioskowania statystycznego:
- Dobór warstwowy: Pozwala na obliczenie błędu próbkowania i przedziałów ufności, umożliwiając formalne wnioskowanie statystyczne.
- Dobór kwotowy: Nie pozwala na obliczenie błędu próbkowania, co ogranicza możliwości formalnego wnioskowania statystycznego.
- Kontrola procesu doboru:
- Dobór warstwowy: Każdy etap procesu doboru jest kontrolowany przez badacza – od definicji warstw po losowy wybór jednostek w warstwach.
- Dobór kwotowy: Ostateczny wybór respondentów pozostaje w rękach ankieterów, co może wprowadzać nieświadome obciążenia.
- Praktyczne wdrożenie:
- Dobór warstwowy: Wymaga operatu losowania (kompletnej listy populacji) do przeprowadzenia losowania.
- Dobór kwotowy: Nie wymaga operatu losowania, a jedynie znajomości rozkładu kluczowych cech w populacji.
Jak dokładnie powstaje próba kwotowa w badaniach CATI lub CAPI
Proces tworzenia próby kwotowej w badaniach CATI (Computer-Assisted Telephone Interviewing) lub CAPI (Computer-Assisted Personal Interviewing) obejmuje następujące etapy:
- Etap planowania i przygotowania:
- Określenie zmiennych kwotowych: Najczęściej są to podstawowe zmienne demograficzne: płeć, wiek, wykształcenie, miejsce zamieszkania (miasto/wieś), region.
- Ustalenie wielkości kwot: Na podstawie danych GUS lub innych wiarygodnych źródeł danych (np. Diagnoza Społeczna) określa się, jaki procent populacji stanowią poszczególne kategorie.
- Przygotowanie tabeli kwotowej: Tworzy się wielowymiarową macierz kwot, np. ile powinno być kobiet w wieku 18-29 lat z wyższym wykształceniem mieszkających na wsi w województwie mazowieckim.
- Przygotowanie operacyjne badania CATI:
- Przygotowanie bazy telefonicznej: W przypadku CATI tworzy się bazę numerów telefonicznych (stacjonarnych i/lub komórkowych).
- Losowanie numerów z puli: Często stosuje się metodę RDD (Random Digit Dialing) dla telefonów komórkowych lub losowanie z książek telefonicznych (coraz rzadziej) dla telefonów stacjonarnych.
- Przypisanie numerów do zespołów ankieterskich: System CATI dystrybuuje numery do ankieterów.
- Realizacja badania CATI:
- Pytania filtrujące: Na początku rozmowy ankieter zadaje pytania o wiek, płeć i inne zmienne kwotowe.
- Decyzja o kontynuacji: System CATI na bieżąco monitoruje wypełnienie kwot i decyduje, czy dana osoba kwalifikuje się do badania (czy jej profil demograficzny jest jeszcze potrzebny w próbie).
- Realizacja wywiadu: Jeśli respondent pasuje do wciąż otwartej kwoty, przeprowadzany jest wywiad.
- Automatyczne zamykanie wypełnionych kwot: Gdy dana kwota zostaje wypełniona, system przestaje przyjmować nowych respondentów o tym profilu.
- Rejestracja odmów udziału w badaniu: System rejestruje odmowy według ich typu (odmowa na etapie wprowadzenia, odmowa po pytaniach filtrujących, przerwanie wywiadu) oraz dane demograficzne, jeśli zostały zebrane przed odmową.
- Przygotowanie operacyjne badania CAPI:
- Wybór lokalizacji: Wybiera się punkty realizacji badania, często stratyfikowane według regionów, wielkości miejscowości itd.
- Instrukcje dla ankieterów: Ankieterzy otrzymują szczegółowe instrukcje dotyczące kwot, które muszą wypełnić w swoim rejonie.
- Realizacja badania CAPI:
- Screener: Ankieter używa krótkiego kwestionariusza selekcyjnego do określenia, czy dana osoba spełnia kryteria kwotowe.
- Dobór respondenta: Ankieter sam decyduje, kogo zapytać o udział w badaniu, kierując się wytycznymi kwotowymi.
- Monitorowanie realizacji kwot: Ankieterzy regularnie raportują zrealizowane wywiady, a koordynator badania monitoruje wypełnienie kwot.
- Kontrola jakości i analiza odmów:
- Weryfikacja wywiadów: Losowo wybrane wywiady są weryfikowane przez ponowny kontakt z respondentem.
- Kontrola pracy ankieterów: W badaniach CAPI często stosuje się geolokalizację ankieterów, żeby potwierdzić, że faktycznie byli w deklarowanych lokalizacjach.
- Kontrola “efektu ankietera”: Analizuje się, czy określeni ankieterzy nie mają systematycznie odmiennych wyników.
- Analiza wskaźnika odpowiedzi (response rate): Oblicza się stosunek zrealizowanych wywiadów do wszystkich nawiązanych kontaktów.
- Analiza struktury odmów: Sprawdza się, czy odmowy nie są systematycznie powiązane z określonymi cechami demograficznymi, co mogłoby wprowadzić błąd.
- Ważenie końcowe (po realizacji badania):
- Korekta nierównomiernej realizacji kwot: Nawet przy najstaranniejszym doborze kwotowym rzadko udaje się idealnie odwzorować strukturę populacji, dlatego stosuje się ważenie danych po zakończeniu zbierania wywiadów.
- Kalibracja do znanych parametrów populacji: Próbę kalibruje się do dokładnych danych z GUS lub innych wiarygodnych źródeł, przypisując odpowiednie wagi poszczególnym respondentom.
- Metody ważenia: Najczęściej stosuje się ważenie brzegowe (rim weighting) lub iteracyjne dopasowywanie (raking), które pozwalają jednocześnie dopasować próbę do wielu zmiennych demograficznych.
Praktyczny przykład realizacji badania CATI z doborem kwotowym w Polsce:
Cel badania: Ogólnopolski sondaż opinii na temat systemu edukacji, n=1000 wywiadów.
Zmienne kwotowe:
- Płeć: 52% kobiety, 48% mężczyźni
- Wiek: 18-29 lat (18%), 30-44 lat (29%), 45-59 lat (25%), 60+ lat (28%)
- Wykształcenie: Podstawowe/gimnazjalne (18%), Zasadnicze zawodowe (23%), Średnie (35%), Wyższe (24%)
- Wielkość miejscowości: Wieś (39%), Miasto do 50 tys. (23%), Miasto 50-200 tys. (16%), Miasto 200+ tys. (22%)
- Region: Poszczególne województwa zgodnie z proporcjami GUS
Przebieg badania:
- System CATI losuje numery telefonów i przydziela ankieterom
- Ankieter przeprowadza wywiad, jeśli respondent spełnia kryteria kwotowe i się zgadza
- System monitoruje wypełnienie kwot i automatycznie zamyka te, które osiągnęły zakładaną liczebność
- W trakcie realizacji badania okazuje się, że najtrudniej dotrzeć do mężczyzn z wykształceniem zasadniczym zawodowym w wieku 45-59 lat – ankieterom przydzielane są dodatkowe godziny na poszukiwanie respondentów o tym profilu
- Po zakończeniu zbierania danych, próba jest ważona, aby skorygować niewielkie odchylenia od założonych kwot
Dlaczego Ośrodki Badania Opinii Coraz Częściej Stosują Dobór Kwotowy
W ostatnich latach wiele ośrodków badania opinii publicznej przeszło na metody doboru kwotowego z kilku kluczowych powodów:
Spadające Wskaźniki Realizacji: Tradycyjne badania telefoniczne oparte na losowym doborze odnotowały spadek wskaźników odpowiedzi z około 36% w latach 90. do mniej niż 10% obecnie. Zwiększa to koszty i potencjalnie wprowadza błąd związany z odmowami, który może być gorszy niż błąd selekcji wynikający z metod nielosowych.
Problemy z Dotarciem do Respondentów: Losowe wybieranie numerów telefonicznych nie zapewnia już reprezentatywnej próby populacji, ponieważ wielu ludzi zrezygnowało z telefonów stacjonarnych na rzecz komórkowych, a wielu nie odbiera połączeń od nieznanych numerów.
Efektywność Kosztowa: Badania oparte na losowym doborze stały się niezwykle drogie wraz ze spadkiem wskaźników odpowiedzi, podczas gdy panele internetowe i dobór kwotowy są bardziej przystępne cenowo.
Szybkość: W szybko zmieniających się kampaniach politycznych lub gwałtownie ewoluujących sytuacjach społecznych, dobór kwotowy może dostarczyć wyniki znacznie szybciej niż metody losowe.
Udoskonalenia w Technikach Ważenia: Nowoczesne metody statystyczne pozwalają badaczom dostosować próby kwotowe, aby lepiej reprezentowały populację docelową poprzez ważenie odpowiedzi w oparciu o znane parametry populacji.
Podejścia Mieszane: Wielu badaczy stosuje obecnie metody mieszane, które łączą elementy doboru losowego i nielosowego, z zaawansowanym ważeniem i modelowaniem w celu poprawy dokładności.
Wpływ odmów na jakość próby i praktyczne problemy realizacji badań
Problem odmów udziału w badaniach
Odmowy udziału w badaniu stanowią jedno z największych wyzwań współczesnej metodologii badawczej i mają istotny wpływ na jakość uzyskiwanych wyników:
- Skala zjawiska:
- W klasycznych badaniach kwestionariuszowych poziom realizacji (response rate) w Polsce spadł z około 70-80% w latach 90. do 30-40% obecnie.
- W badaniach telefonicznych CATI współczynnik odpowiedzi wynosi często zaledwie 5-15%.
- W badaniach internetowych na panelach wskaźnik odpowiedzi może wynosić 20-30%, ale wśród respondentów dobieranych z ogółu populacji spada nawet do 1-2%.
- Typy odmów:
- Odmowy “twarde” – kategoryczna odmowa udziału w jakimkolwiek badaniu.
- Odmowy “miękkie” – wymówki typu “nie mam czasu”, “jestem zajęty”, które mogą wynikać z niechęci do tematu badania.
- Odmowy selektywne – odmowy udziału w badaniach na określone tematy (np. polityczne, dotyczące zdrowia).
- Niedostępność – niemożność nawiązania kontaktu z wylosowaną osobą mimo wielokrotnych prób.
- Konsekwencje dla jakości badań:
- Błąd systematyczny – jeśli osoby odmawiające udziału systematycznie różnią się od osób uczestniczących w badaniu pod względem kluczowych zmiennych.
- Zawężenie próby do “zawodowych respondentów” – szczególnie w panelach internetowych, gdzie uczestniczą głównie osoby chętne do udziału w wielu badaniach.
- Nadreprezentacja określonych grup – np. emerytów i rencistów, którzy częściej mają czas i chęć na udział w badaniach osobistych.
- Metody radzenia sobie z odmowami:
- Ponowne próby kontaktu – standardem jest wykonanie minimum 3-4 prób kontaktu w różnych dniach i porach.
- Dostosowanie terminu – oferowanie elastycznych terminów realizacji wywiadu.
- Zachęty materialne – oferowanie drobnych gratyfikacji za udział w badaniu.
- Analiza i ważenie ze względu na odmowy – uwzględnianie struktury osób odmawiających w procesie ważenia danych.
- Techniki konwersji odmów – specjalne szkolenia dla ankieterów w zakresie przekonywania osób początkowo odmawiających.
- Dokumentacja odmów:
- Standard AAPOR (American Association for Public Opinion Research) – zaleca dokładne raportowanie wszystkich kontaktów, odmów i przyczyn braku realizacji wywiadu.
- Kategorie dokumentacji – liczba połączeń/wizyt, powody niedostępności, typy i przyczyny odmów.
- Transparentność metodologiczna – raportowanie wskaźnika odpowiedzi oraz potencjalnego wpływu odmów na wyniki.
Praktyczne problemy realizacji badań probabilistycznych w Polsce:
Brak dostępu do operatu losowania: W Polsce nie ma łatwego dostępu do pełnych i aktualnych rejestrów populacji dla celów badawczych.
Problem z realizacją wywiadów pod wylosowanymi adresami: Coraz trudniej przeprowadzić wywiady pod konkretnymi adresami ze względu na:
- Zwiększoną liczbę zamkniętych osiedli
- Spadek zaufania społecznego i niechęć do wpuszczania ankieterów do domów
- Różne godziny pracy potencjalnych respondentów wymagające wielokrotnych wizyt
Koszt realizacji: Badania z prawdziwym losowym doborem próby (np. metodą random route) są kilkukrotnie droższe niż badania kwotowe.
Wybory prezydenckie w USA w 2016 roku, gdzie wiele sondaży nie przewidziało dokładnie wyniku, doprowadziły do znacznych przemyśleń wśród ankieterów. Zamiast rezygnować z próbkowania kwotowego, wiele organizacji udoskonaliło swoje metody, koncentrując się na lepszych definicjach kwot, ulepszonych technikach ważenia i bardziej przejrzystym raportowaniu ograniczeń metodologicznych.
Pomimo tych trendów, ważne jest, aby zauważyć, że próbkowanie probabilistyczne pozostaje złotym standardem wnioskowania statystycznego. Dobrze zaprojektowane próby probabilistyczne wciąż zapewniają najbardziej niezawodną podstawę do uogólniania z próby na populację, szczególnie w badaniach akademickich, gdzie dokładność jest priorytetem nad kosztem i szybkością.
Rodzaje Błędów Statystycznych - Poprawiona Klasyfikacja
Błąd Systematyczny a Błąd Losowy
Błędy systematyczne i błędy losowe reprezentują fundamentalnie różne sposoby, w jakie pomiary mogą odbiegać od prawdziwych wartości:
- Błąd Systematyczny (Obciążenie)
- Definicja: Konsekwentne, przewidywalne odchylenia od prawdziwej wartości w określonym kierunku.
- Cechy:
- Skutkuje pomiarami, które są stale zbyt wysokie lub zbyt niskie
- Nie zmniejsza się wraz ze zwiększeniem wielkości próby
- Można go skorygować, jeśli zostanie zidentyfikowany
- Przykłady:
- Waga, która zawsze pokazuje o 1 kilogram więcej niż rzeczywista waga
- Błąd selekcji wynikający z pominięcia niektórych grup populacji
- Tendencyjne pytania w ankiecie, które skłaniają respondentów do konkretnych odpowiedzi
- Wykrywanie i Korekta:
- Kalibracja wobec znanych wzorców
- Porównanie z pomiarami przy użyciu różnych metod
- Staranne projektowanie badań i wstępne testowanie narzędzi badawczych
- Błąd Losowy
- Definicja: Nieprzewidywalne wahania w pomiarach wynikające z czynników przypadkowych.
- Cechy:
- Zmienia się zarówno pod względem wielkości, jak i kierunku w różnych pomiarach
- Zwykle podlega rozkładowi normalnemu
- Zmniejsza się wraz ze wzrostem wielkości próby (zależność √n)
- Przykłady:
- Naturalne różnice biologiczne między badanymi osobami
- Drobne wahania w przyrządach pomiarowych
- Warunki środowiskowe, które przypadkowo zmieniają się podczas pomiaru
- Sposoby ograniczania:
- Zwiększanie wielkości próby
- Wykonywanie powtórzonych pomiarów
- Poprawa precyzji pomiarów
Błędy Związane z Próbą a Błędy Niezwiązane z Próbą
To rozróżnienie koncentruje się na źródle błędów w badaniach statystycznych:
- Błąd Związany z Próbą (Błąd Próby)
- Definicja: Różnica między statystyką próby a prawdziwym parametrem populacji wynikająca z losowych wahań w doborze.
- Cechy:
- Nieunikniony w każdym badaniu opartym na próbie
- Można go obliczyć za pomocą miar statystycznych (błąd standardowy, przedziały ufności)
- Zmniejsza się w przewidywalny sposób wraz ze wzrostem wielkości próby
- Zawsze ma charakter losowy (nie systematyczny)
- Przykłady:
- Losowa próba pokazująca 52% poparcia dla polityki, gdy prawdziwa wartość w populacji wynosi 50%
- Zróżnicowanie średniego dochodu w różnych losowych próbach z tej samej populacji
- Metody kontroli:
- Zwiększanie wielkości próby
- Stosowanie bardziej efektywnych schematów doboru próby (np. warstwowanie)
- Zastosowanie odpowiednich wag w analizie danych
- Błąd Niezwiązany z Próbą (Błąd Niesamplowy)
- Definicja: Wszystkie błędy, które nie wynikają z losowych wahań w doborze próby, występujące zarówno w badaniach na próbie, jak i w pełnych spisach.
- Cechy:
- Może być systematyczny lub losowy
- Często trudniejszy do wykrycia i zmierzenia niż błąd próby
- Niekoniecznie zmniejsza się wraz ze zwiększeniem próby
- Potencjalnie bardziej szkodliwy dla trafności badań niż błąd próby
- Rodzaje i Przykłady:
- Błąd Pokrycia (systematyczny): Korzystanie z listy wyborców, która nie obejmuje osób niedawno zarejestrowanych
- Błąd Braku Odpowiedzi (może być systematyczny lub losowy): Wyższy wskaźnik odmów wśród określonych grup demograficznych
- Błąd Pomiaru (może być systematyczny lub losowy):
- Systematyczny: Źle sformułowane pytania, które konsekwentnie zniekształcają odpowiedzi
- Losowy: Sporadyczne błędy przy wprowadzaniu danych
- Błąd Przetwarzania (może być systematyczny lub losowy):
- Systematyczny: Konsekwentne niewłaściwe kodowanie określonych odpowiedzi
- Losowy: Przypadkowe błędy w transkrypcji
Model Całkowitego Błędu Badania
Nowoczesna metodologia badawcza analizuje błędy poprzez model Całkowitego Błędu Badania (Total Survey Error), który uwzględnia wszystkie źródła błędów mogących wpływać na jakość badania:
- Błędy Reprezentacji (wpływające na to, kto jest uwzględniony):
- Błąd pokrycia
- Błąd próby
- Błąd braku odpowiedzi
- Błąd wynikający z procedur ważenia danych
- Błędy Pomiaru (wpływające na dokładność odpowiedzi):
- Błąd specyfikacji (mierzenie niewłaściwego zjawiska)
- Błąd pomiaru (wpływ respondenta, ankietera, kwestionariusza)
- Błąd przetwarzania (wprowadzanie danych, kodowanie, edytowanie)
Zrozumienie wzajemnego oddziaływania między tymi rodzajami błędów jest kluczowe dla projektowania wysokiej jakości badań i właściwej interpretacji wyników. Chociaż błąd próby zwraca na siebie większą uwagę, ponieważ łatwiej go mierzyć, błędy niezwiązane z próbą często stanowią większe zagrożenie dla trafności i rzetelności współczesnych badań.
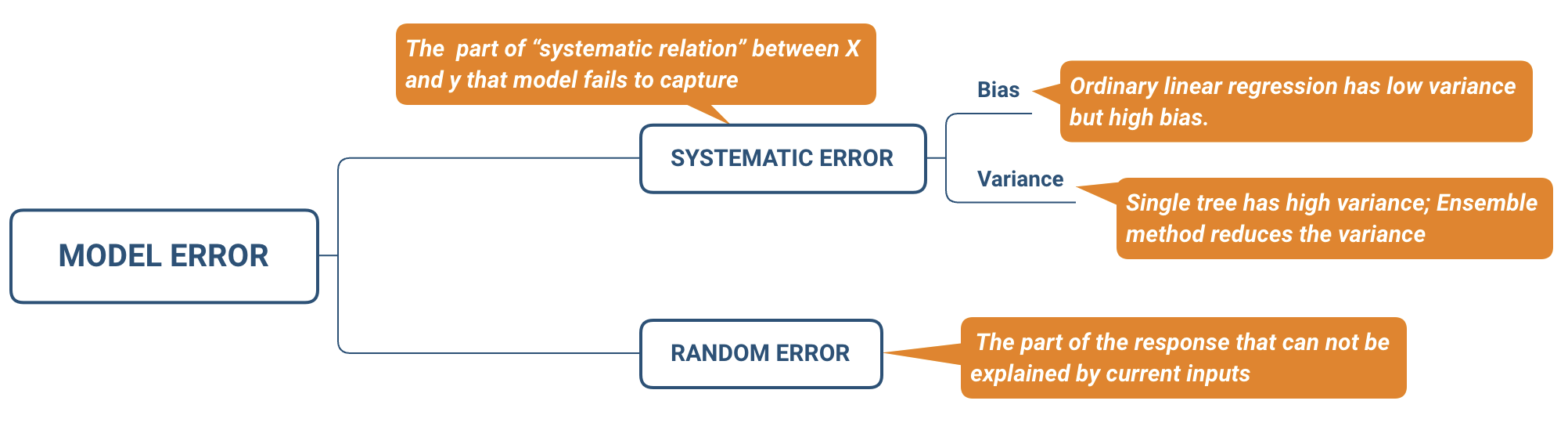
Rysunek: Związek między złożonością modelu, błędem systematycznym (obciążeniem) i wariancją. Ilustruje to, jak równowaga między błędem systematycznym a błędem losowym (wariancją) wpływa na ogólny błąd modelu.