Statystyki opisowe są fundamentalnymi narzędziami w badaniach nauk społecznych, zapewniającymi zwięzłe podsumowanie charakterystyk danych. Pełnią kilka kluczowych funkcji:
Podsumowanie dużych zbiorów danych w przystępne informacje
Identyfikacja wzorców i trendów w danych
Wykrywanie potencjalnych anomalii lub wartości odstających
Zapewnienie podstawy do dalszej analizy statystycznej
6.1 Wprowadzenie do Notacji Sigma (Σ)
Co to jest notacja sumacyjna Sigma? Sigma (Σ) to operator matematyczny, który nakazuje nam zsumować (dodać) sekwencję wyrazów - działa jak instrukcja wykonania dodawania wszystkich elementów w określonym zakresie.
Cel: Zapewnia zwięzły sposób zapisu sum wielu podobnych wyrazów za pomocą jednego symbolu, unikając długich wyrażeń dodawania.
Podstawowa formuła
Ogólna forma notacji sigma to:
\sum_{i=a}^{b} f(i)
Indeks sumowania:i
Dolna granica:a
Górna granica:b
Funkcja:f(i)
Przykłady zastosowania notacji Sigma
Prosty przykład: Suma liczb naturalnych
Załóżmy, że chcesz dodać pierwsze pięć dodatnich liczb całkowitych:
\sum_{i=1}^{5} i = 1 + 2 + 3 + 4 + 5 = 15
Powyższy zapis dodaje pierwsze pięć dodatnich liczb całkowitych.
Suma kwadratów
Załóżmy, że chcesz zsumować kwadraty pierwszych czterech dodatnich liczb całkowitych:
Rozkład danych informuje o tym, jakie wartości przyjmuje zmienna i jak często.
Zrozumienie rozkładów danych jest kluczowe dla analizy i wizualizacji danych. W tym dokumencie przyjrzymy się różnym typom rozkładów i sposobom ich wizualizacji przy użyciu ggplot2 w R.
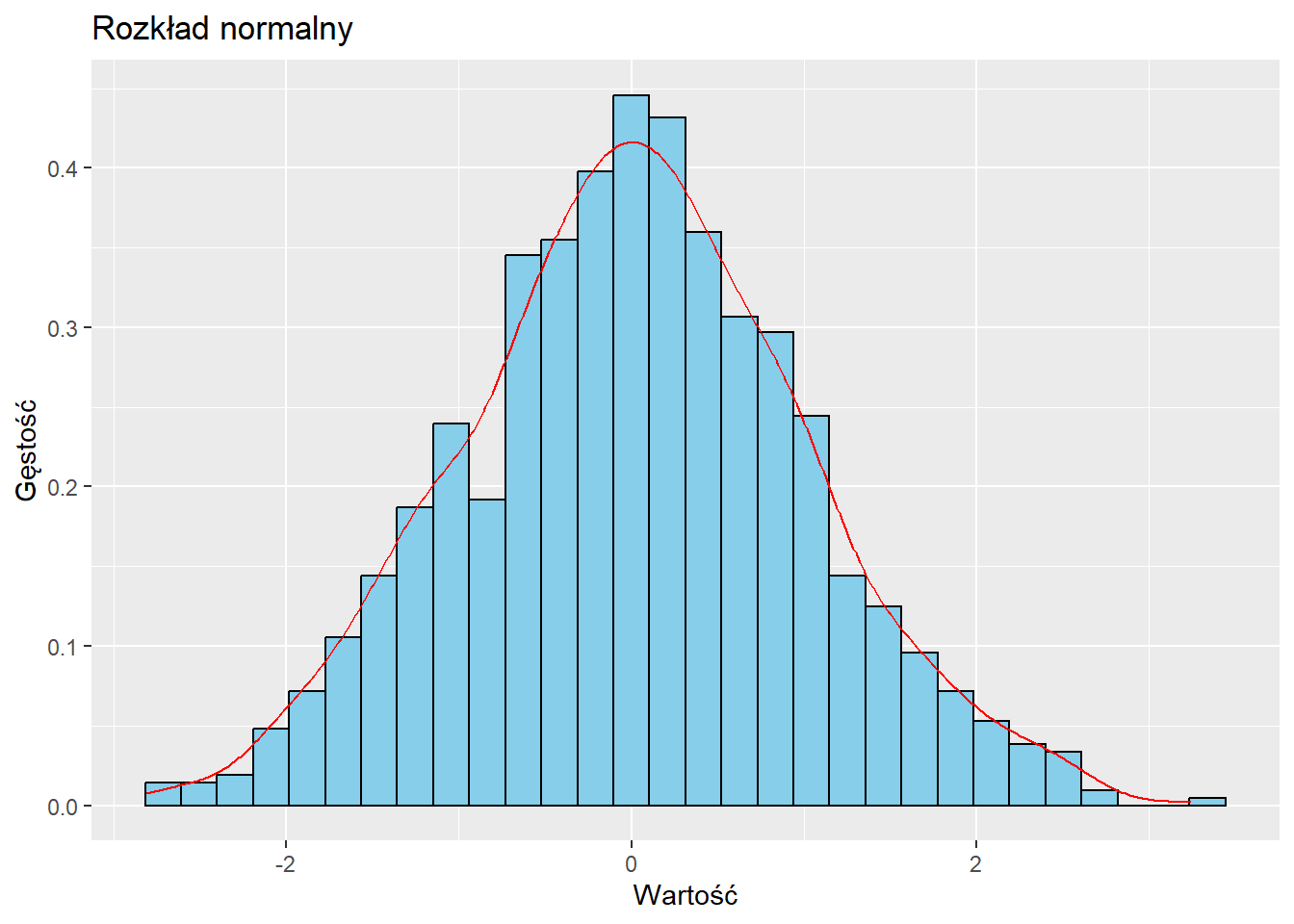
Rozkład normalny
Rozkład normalny, znany również jako rozkład Gaussa, jest symetryczny i ma kształt dzwonu.
# Generowanie danych o rozkładzie normalnymdane_normalne <-data.frame(x =rnorm(1000))# Wykresggplot(dane_normalne, aes(x)) +geom_histogram(aes(y = ..density..), bins =30, fill ="skyblue", color ="black") +geom_density(color ="red") +labs(title ="Rozkład normalny", x ="Wartość", y ="Gęstość")
Warning: The dot-dot notation (`..density..`) was deprecated in ggplot2 3.4.0.
ℹ Please use `after_stat(density)` instead.
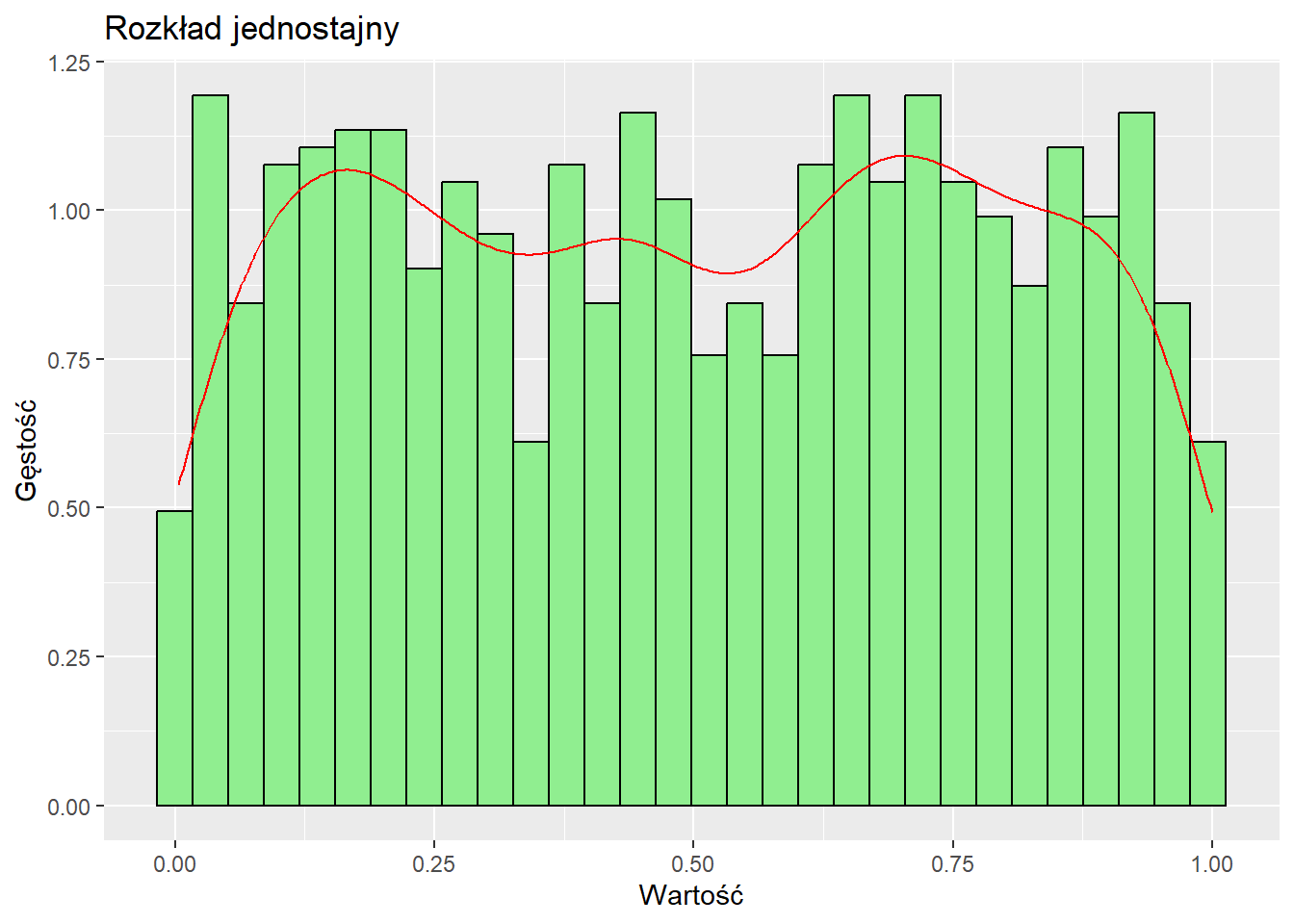
Rozkład jednostajny
W rozkładzie jednostajnym wszystkie wartości mają równe prawdopodobieństwo wystąpienia.
# Generowanie danych o rozkładzie jednostajnymdane_jednostajne <-data.frame(x =runif(1000))# Wykresggplot(dane_jednostajne, aes(x)) +geom_histogram(aes(y = ..density..), bins =30, fill ="lightgreen", color ="black") +geom_density(color ="red") +labs(title ="Rozkład jednostajny", x ="Wartość", y ="Gęstość")
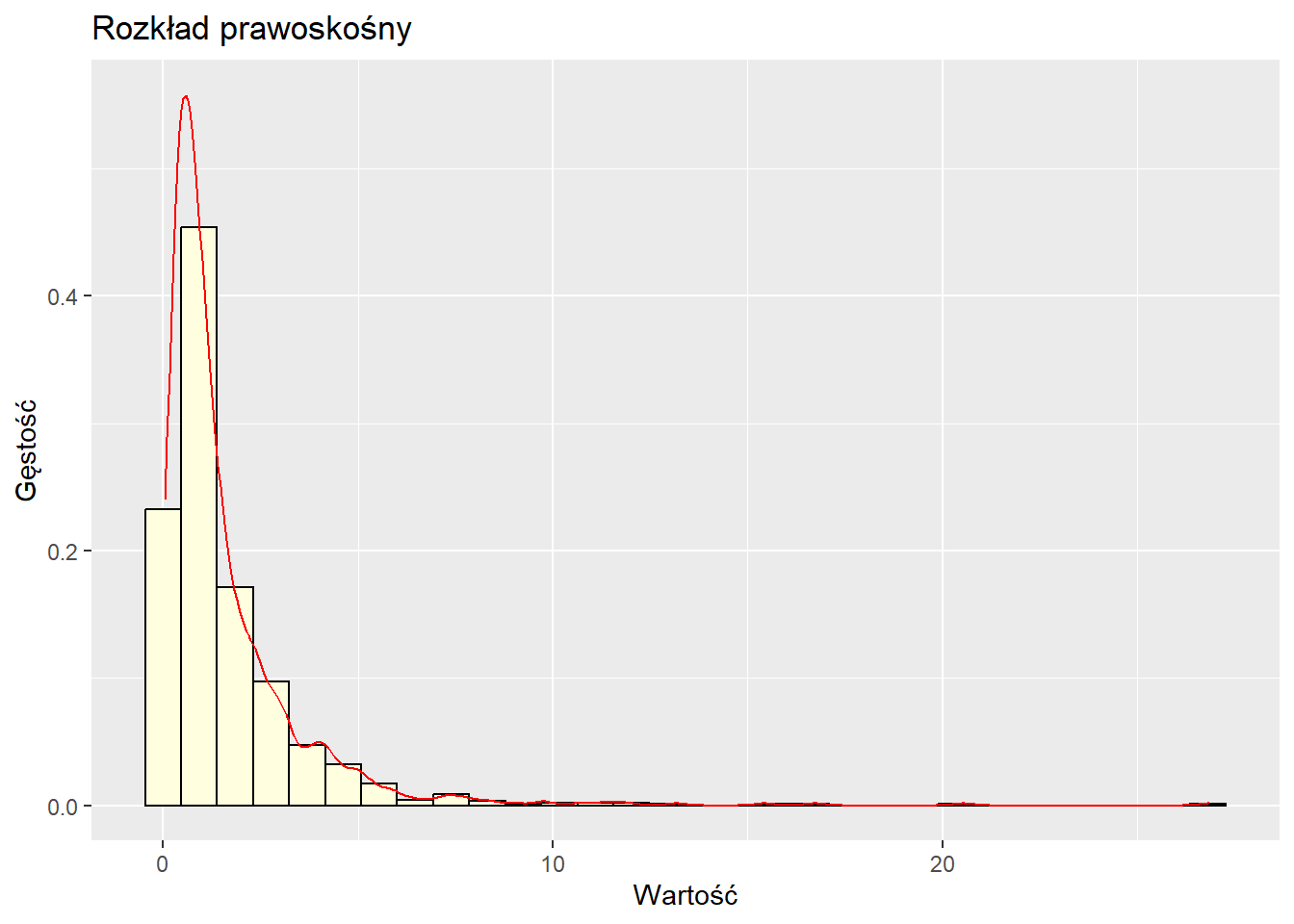
Rozkłady skośne
Rozkłady skośne są asymetryczne, z jednym ogonem dłuższym niż drugi.
# Generowanie danych o rozkładzie prawoskośnymdane_prawoskosne <-data.frame(x =rlnorm(1000))# Wykresggplot(dane_prawoskosne, aes(x)) +geom_histogram(aes(y = ..density..), bins =30, fill ="lightyellow", color ="black") +geom_density(color ="red") +labs(title ="Rozkład prawoskośny", x ="Wartość", y ="Gęstość")
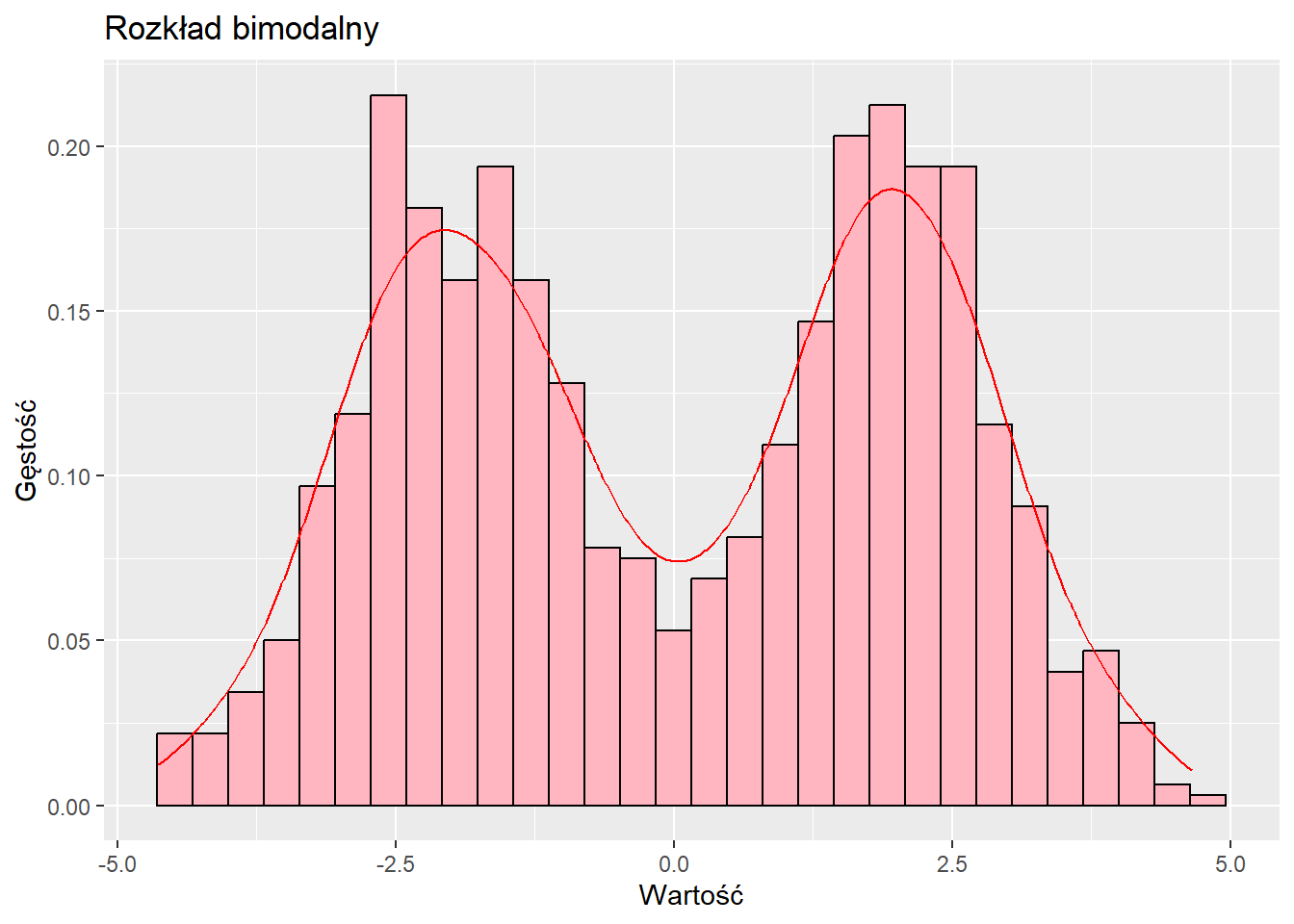
Rozkład bimodalny
Rozkład bimodalny ma dwa szczyty (dwie dominanty), wskazujące na dwie odrębne podgrupy w danych.
# Generowanie danych bimodalnychdane_bimodalne <-data.frame(x =c(rnorm(500, mean =-2), rnorm(500, mean =2)))# Wykresggplot(dane_bimodalne, aes(x)) +geom_histogram(aes(y = ..density..), bins =30, fill ="lightpink", color ="black") +geom_density(color ="red") +labs(title ="Rozkład bimodalny", x ="Wartość", y ="Gęstość")
Rozkład
Kluczowe właściwości
Przykłady
Symetryczny (Normalny)
Symetryczny, kształt dzwonu, większość wartości blisko średniej
Wzrost dorosłych w populacji, wyniki testów IQ, błędy pomiarowe, wyniki egzaminów standaryzowanych
Równomierny (Jednostajny)
Jednakowe prawdopodobieństwo w całym zakresie
Ostatnia cyfra numeru telefonu, wybór losowego dnia tygodnia, pozycja wskazówki po zakręceniu kołem fortuny
Dwumodalny (Bimodalny)
Dwa wyraźne szczyty, sugeruje istnienie podgrup
Struktura wieku w miastach uniwersyteckich (studenci i stali mieszkańcy), opinie na tematy silnie polaryzujące społeczeństwo, godziny natężenia ruchu drogowego (poranny i popołudniowy szczyt)
Skośny w prawo (Prawostronnie asymetryczny)
Wydłużony “ogon” po prawej stronie, większość wartości mniejsza od średniej
Czas oczekiwania w kolejce, czas dojazdu do pracy, wiek zawarcia pierwszego małżeństwa
Skośny z grubym ogonem (Log-normalny)
Silna asymetria w prawo, wartości nie mogą być ujemne, długi “gruby ogon”
Dochody osobiste, ceny mieszkań, wielkość gospodarstw domowych
Skośny o ekstremalnym ogonie (Potęgowy)
Ekstremalna asymetria, efekt “bogaty staje się bogatszym”, brak charakterystycznej skali
Majątek najbogatszych osób, populacja miast, liczba obserwujących w mediach społecznościowych, liczba cytowań publikacji naukowych
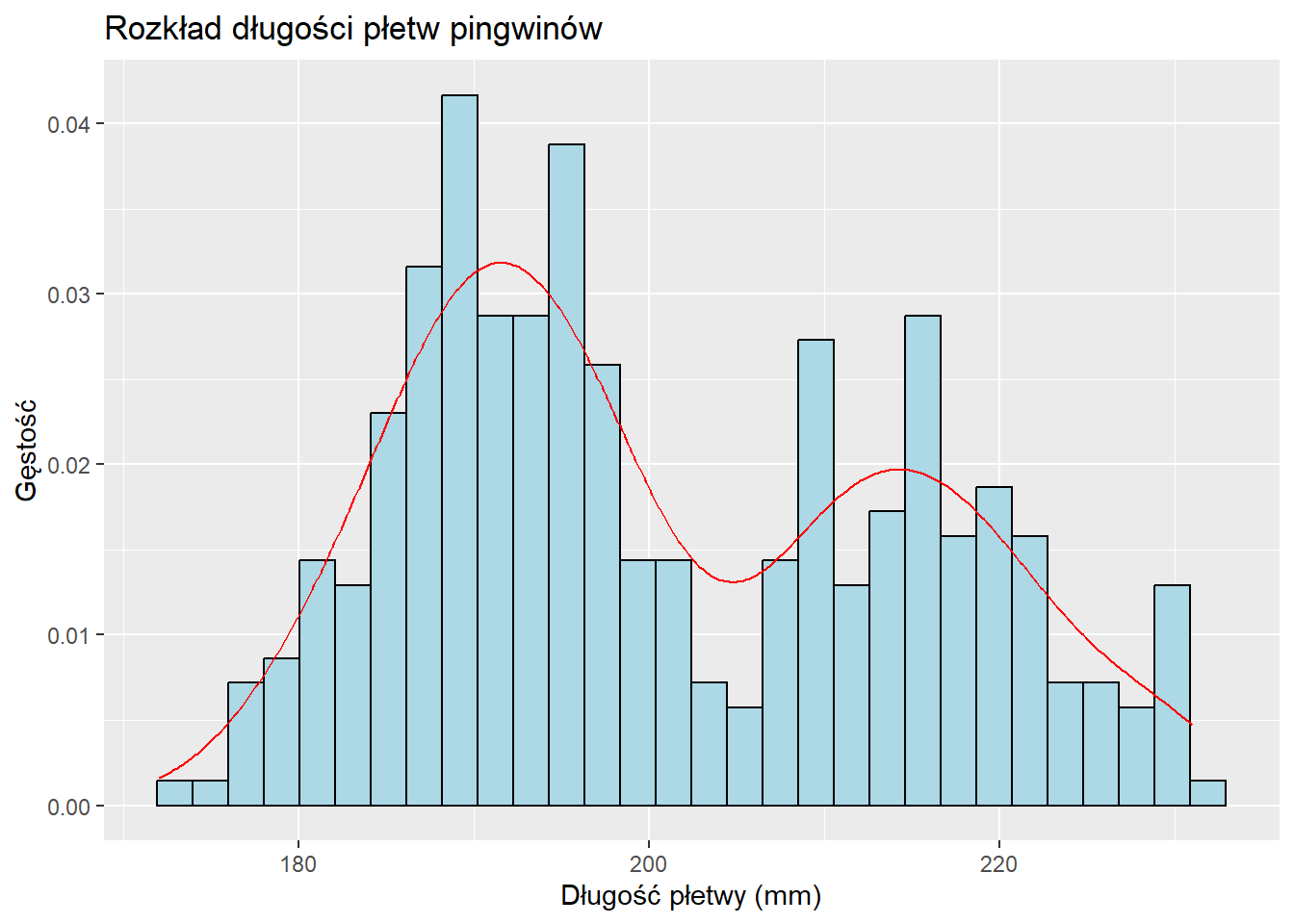
6.3 Wizualizacja rozkładów danych rzeczywistych
Użyjemy zbioru danych palmerpenguins do wizualizacji rozkładów danych.
Histogram i wykres gęstości
Understanding Histograms and Density
⭐ A histogram is a special graph for numerical data where:
Data is grouped into ranges (called “bins”)
Bars touch each other (unlike bar charts!) because the data is continuous
Each bar’s height shows how many values fall into that range
Think of density as showing how common or concentrated certain values are in your data:
A higher point on a density curve (or taller bar in a histogram) means those values appear more frequently in your data
A lower point means those values are less common
Just like a crowded area has more people per space (higher density), a taller part of the graph shows values that appear more often in your dataset!
ggplot(penguins, aes(x = flipper_length_mm)) +geom_histogram(aes(y = ..density..), bins =30, fill ="lightblue", color ="black") +geom_density(color ="red") +labs(title ="Rozkład długości płetw pingwinów", x ="Długość płetwy (mm)", y ="Gęstość")
Warning: Removed 2 rows containing non-finite outside the scale range
(`stat_bin()`).
Warning: Removed 2 rows containing non-finite outside the scale range
(`stat_density()`).
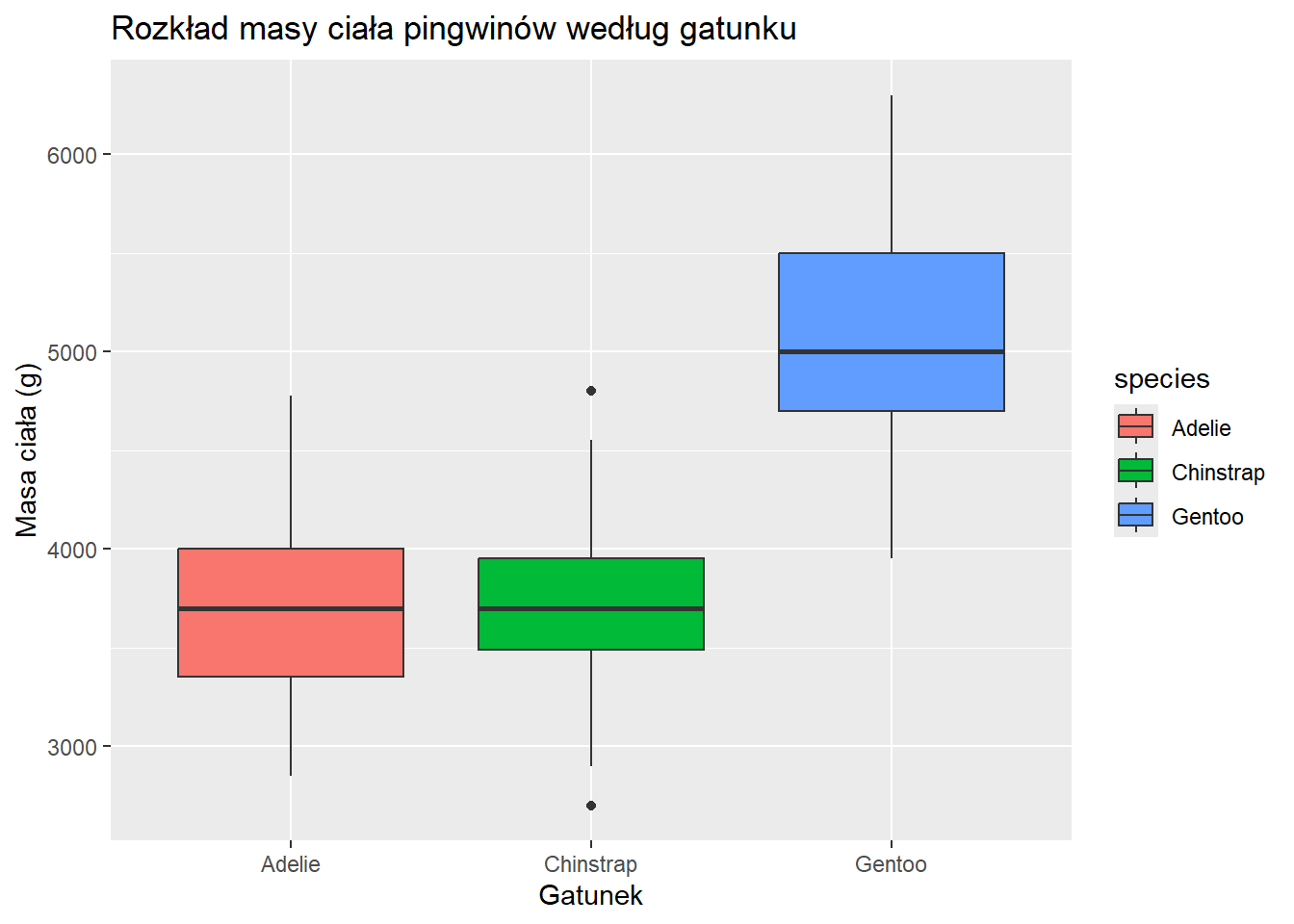
Wykres pudełkowy
Wykresy pudełkowe są przydatne do porównywania rozkładów między kategoriami.
ggplot(penguins, aes(x = species, y = body_mass_g, fill = species)) +geom_boxplot() +labs(title ="Rozkład masy ciała pingwinów według gatunku", x ="Gatunek", y ="Masa ciała (g)")
Warning: Removed 2 rows containing non-finite outside the scale range
(`stat_boxplot()`).
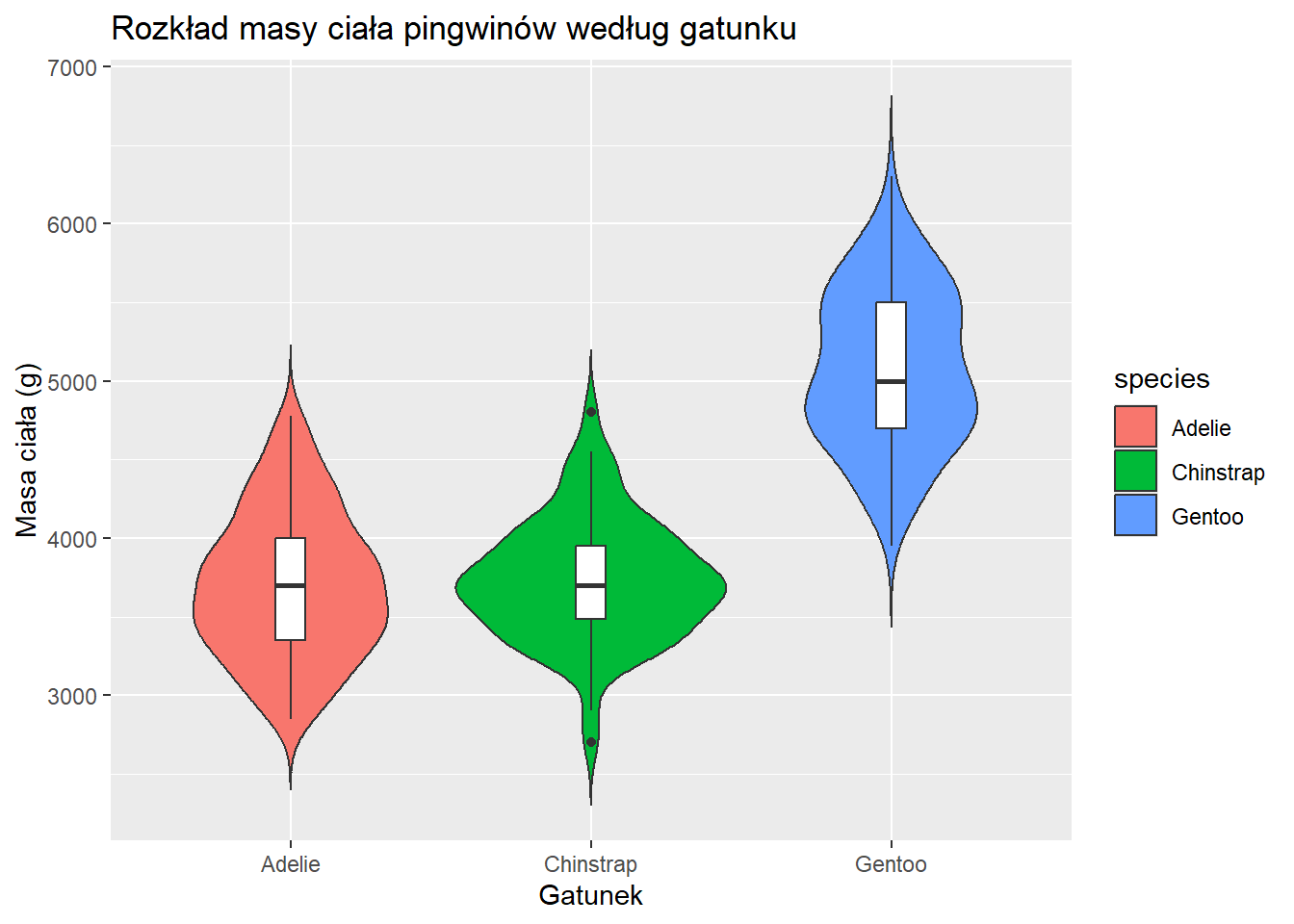
Wykres skrzypcowy
Wykresy skrzypcowe łączą cechy wykresu pudełkowego i wykresu gęstości.
ggplot(penguins, aes(x = species, y = body_mass_g, fill = species)) +geom_violin(trim =FALSE) +geom_boxplot(width =0.1, fill ="white") +labs(title ="Rozkład masy ciała pingwinów według gatunku", x ="Gatunek", y ="Masa ciała (g)")
Warning: Removed 2 rows containing non-finite outside the scale range
(`stat_ydensity()`).
Warning: Removed 2 rows containing non-finite outside the scale range
(`stat_boxplot()`).
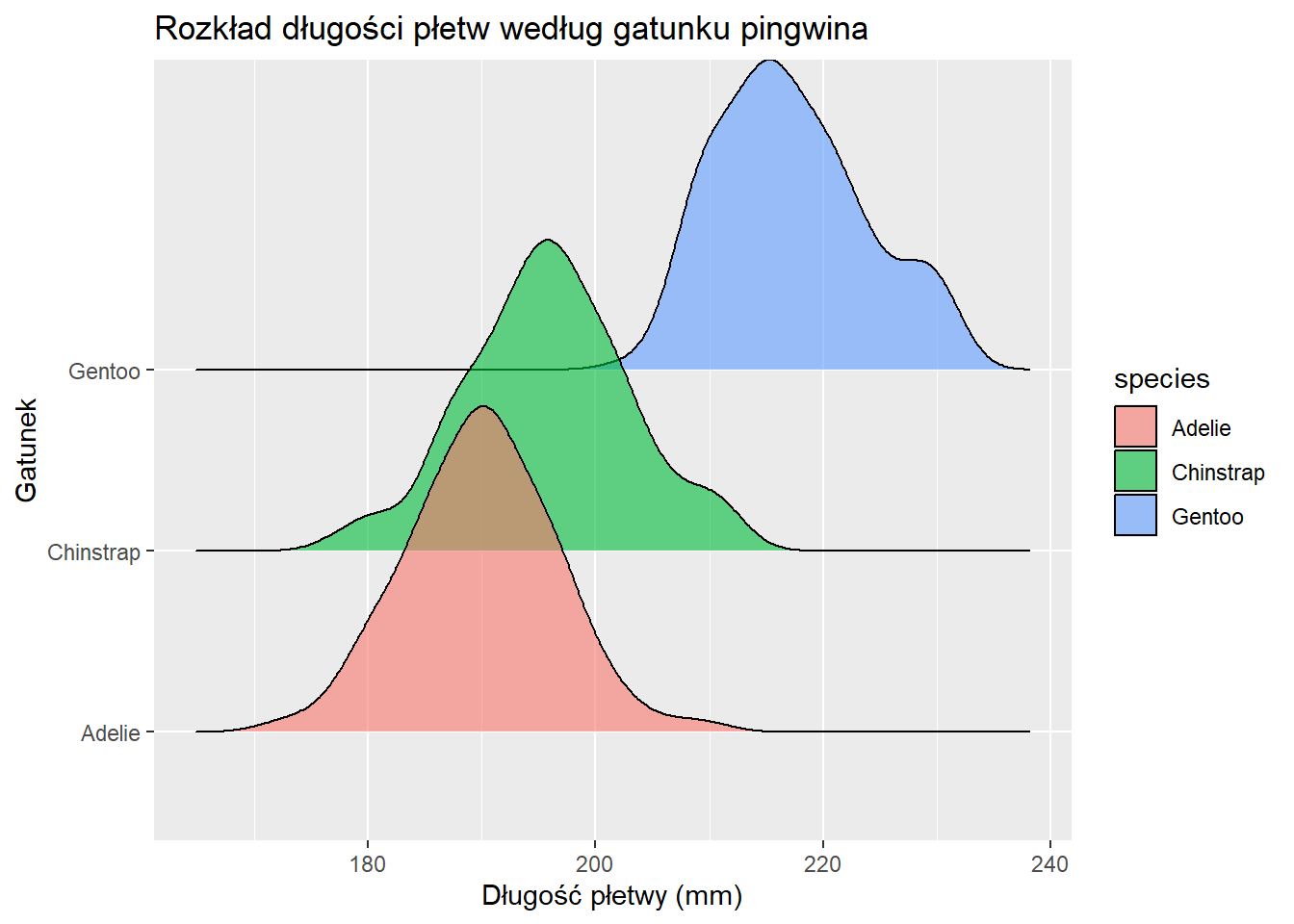
Wykres grzbietowy
Wykresy grzbietowe są przydatne do porównywania wielu rozkładów.
library(ggridges)ggplot(penguins, aes(x = flipper_length_mm, y = species, fill = species)) +geom_density_ridges(alpha =0.6) +labs(title ="Rozkład długości płetw według gatunku pingwina",x ="Długość płetwy (mm)",y ="Gatunek")
Picking joint bandwidth of 2.38
Warning: Removed 2 rows containing non-finite outside the scale range
(`stat_density_ridges()`).
Podsumowanie
Zrozumienie i wizualizacja rozkładów danych są kluczowe w analizie danych. ggplot2 zapewnia elastyczny i potężny zestaw narzędzi do tworzenia różnych typów wykresów rozkładów. Badając różne techniki wizualizacji, możemy uzyskać wgląd w podstawowe wzorce i charakterystyki naszych danych.
6.4 Wartości Odstające (Outliers)
Przed zagłębieniem się w konkretne miary, kluczowe jest zrozumienie pojęcia wartości odstających, ponieważ mogą one znacząco wpływać na wiele statystyk opisowych.
Wartości odstające to punkty danych, które znacznie różnią się od innych obserwacji w zbiorze danych. Mogą wystąpić z powodu:
Błędów pomiaru lub zapisu
Prawdziwych ekstremalnych wartości w populacji
Wartości odstające mogą mieć istotny wpływ na wiele miar statystycznych, szczególnie tych opartych na średnich lub sumach kwadratów odchyleń. Dlatego ważne jest, aby:
Identyfikować wartości odstające zarówno poprzez metody statystyczne, jak i wiedzę dziedzinową
Badać przyczyny wartości odstających
Podejmować świadome decyzje o tym, czy włączać je do analiz, czy nie
6.5 Symbole Stosowane w Statystyce - podsumowanie
Miara
Parametr Populacji
Statystyka z Próby
Alternatywne Oznaczenia
Uwagi
Liczebność
N
n
-
Całkowita liczba obserwacji
Średnia
\mu
\bar{x}
E(X), M
E(X) stosowane w rachunku prawdopodobieństwa
Wariancja
\sigma^2
s^2
\text{Var}(X), V(X)
Kwadrat odchyleń od średniej
Odchylenie standardowe
\sigma
s
\text{OS}, \text{std}
Pierwiastek z wariancji
Frakcja/Proporcja
\pi, P
\hat{p}
\text{fr}
Częstości względne
Współczynnik korelacji
\rho
r
\text{kor}(x,y)
Wartości od -1 do +1
Błąd standardowy
\sigma_{\bar{x}}
s_{\bar{x}}
\text{BS}
Błąd standardowy średniej
Suma
\sum
\sum
\sum_{i=1}^n
Z indeksowaniem
Pojedyncza obserwacja
X_i
x_i
-
i-ta obserwacja
Kowariancja
\sigma_{xy}
s_{xy}
\text{Cov}(X,Y)
Wspólna zmienność
Mediana
\eta
\text{Me}
M
Wartość środkowa
Rozstęp
R
r
\text{max}(X) - \text{min}(X)
Miara rozproszenia
Dominanta
\text{Mo}
\text{mo}
\text{mod}
Wartość najczęstsza
Skośność
\gamma_1
g_1
\text{SK}
Asymetria rozkładu
Kurtoza
\gamma_2
g_2
\text{KU}
Spłaszczenie rozkładu
Dodatkowe ważne wzory:
Momenty z próby: m_k = \frac{1}{n}\sum_{i=1}^n (x_i - \bar{x})^k
Momenty populacji: \mu_k = E[(X - \mu)^k]
6.6 Miary Tendencji Centralnej
Miary tendencji centralnej mają na celu identyfikację “typowej” lub “centralnej” wartości w zbiorze danych. Trzy podstawowe miary to średnia, mediana i moda.
Średnia Arytmetyczna
Średnia arytmetyczna to suma wszystkich wartości podzielona przez liczbę wartości.
Wzór:\bar{x} = \frac{1}{n}\sum_{i=1}^n x_i
Ważna Właściwość: Średnia jest punktem równowagi w danych. Suma odchyleń od średniej zawsze wynosi zero:
\sum_{i=1}^n (x_i - \bar{x}) = 0
Ta właściwość sprawia, że średnia jest użyteczna w wielu obliczeniach statystycznych.
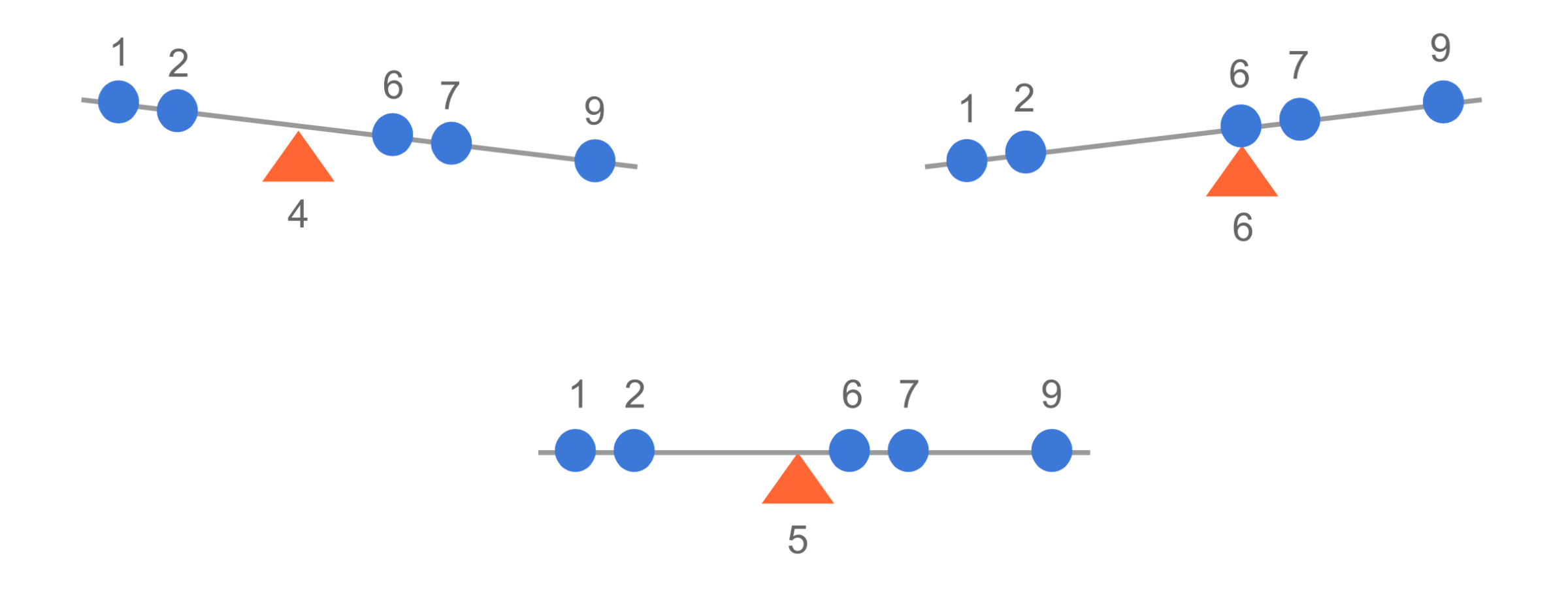
Zrozumienie średniej jako punktu równowagi 🎯
Rozważmy zbiór danych X = \{1, 2, 6, 7, 9\} na osi liczbowej, wyobrażając go sobie jako huśtawkę:
Średnia (\mu) działa jak idealny punkt równowagi tej huśtawki. Dla naszych danych:
\mu = \frac{1 + 2 + 6 + 7 + 9}{5} = 5
Co się dzieje przy różnych punktach podparcia? 🤔
Punkt podparcia w 6 (za wysoko):
Lewa strona: Wartości (1, 2) są poniżej
Prawa strona: Wartości (7, 9) są powyżej
\sum odległości z lewej = (6-1) + (6-2) = 9
\sum odległości z prawej = (7-6) + (9-6) = 4
Huśtawka przechyla się w lewo! ⬅️ bo 9 > 4
Punkt podparcia w 4 (za nisko):
Lewa strona: Wartości (1, 2) są poniżej
Prawa strona: Wartości (6, 7, 9) są powyżej
\sum odległości z lewej = (4-1) + (4-2) = 5
\sum odległości z prawej = (6-4) + (7-4) + (9-4) = 10
Huśtawka przechyla się w prawo! ➡️ bo 5 < 10
Punkt podparcia w średniej (5) (idealna równowaga):
\sum odległości poniżej = \sum odległości powyżej
((5-1) + (5-2)) = ((6-5) + (7-5) + (9-5))
7 = 7 ✨ Idealna równowaga!
To pokazuje, dlaczego średnia jest unikalnym punktem równowagi, gdzie:
\sum_{i=1}^n (x_i - \mu) = 0
Huśtawka zawsze będzie się przechylać, chyba że punkt podparcia zostanie umieszczony dokładnie w średniej! 🎪
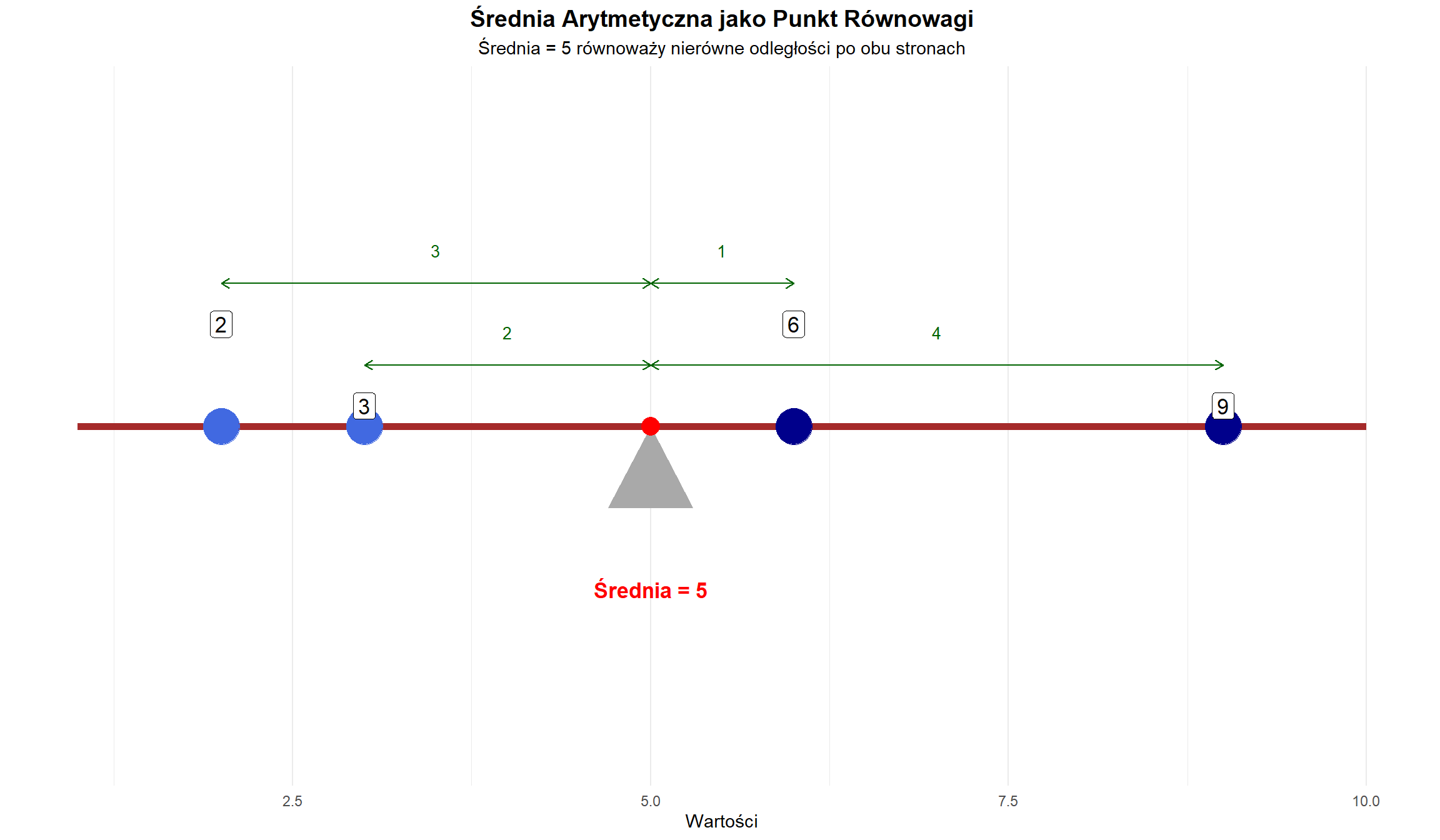
Średnia jako punkt równowagi
Ta wizualizacja pokazuje, jak średnia arytmetyczna (5) działa jako punkt równowagi pomiędzy skupionymi punktami z lewej strony a rozproszonymi punktami z prawej strony:
Lewa strona średniej:
Punkty o wartościach 2 i 3
Blisko siebie (różnica 1 jednostka)
Odległości od średniej: 3 i 2 jednostki
Suma “ciążenia” = 5 jednostek
Prawa strona średniej:
Punkty o wartościach 6 i 9
Bardziej oddalone (różnica 3 jednostki)
Odległości od średniej: 1 i 4 jednostki
Suma “ciążenia” = 5 jednostek
Kluczowe obserwacje:
Średnia (5) jest punktem równowagi, mimo że:
Punkty po lewej są skupione (2,3)
Punkty po prawej są rozproszone (6,9)
Zielone strzałki pokazują odległości od średniej
Równowaga jest zachowana ponieważ:
Suma odległości się równoważy: (5-2) + (5-3) = (6-5) + (9-5)
Całkowita suma odległości = 5 jednostek po każdej stronie
Może nie być dobrą miarą dla silnie asymetrycznych rozkładów danych
Mediana
Mediana to “wartość środkowa”, która dzieli uporządkowane dane na dwie równoliczne połowy. Bardziej precyzyjnie:
Jeśli n jest nieparzyste: Mediana to środkowa obserwacja (ta na pozycji (n+1)/2)
Jeśli n jest parzyste: Mediana to średnia arytmetyczna dwóch środkowych obserwacji (na pozycjach n/2 i n/2 + 1)
Przykład Ręcznego Obliczenia:
Używając tego samego zbioru danych: 2, 4, 4, 5, 5, 7, 9
Krok
Opis
Wynik
1
Uporządkuj dane
2, 4, 4, 5, 5, 7, 9
2
Znajdź środkową wartość
5
Dla parzystej liczby wartości, weź średnią z dwóch środkowych wartości.
Obliczenie w R:
dane <-c(2, 4, 4, 5, 5, 7, 9)median(dane)
[1] 5
Zalety:
Nie jest zniekształcona przez skrajne wartości odstające (outliers)
Lepsza dla rozkładów skośnych
Wady:
Nie wykorzystuje wszystkich punktów danych
Warning
Jak znaleźć pozycję mediany w zbiorze danych:
Najpierw posortuj dane rosnąco
Gdy n jest nieparzyste:
Pozycja mediany = \frac{n + 1}{2}
Gdy n jest parzyste:
Pierwsza pozycja mediany = \frac{n}{2}
Druga pozycja mediany = \frac{n}{2} + 1
Mediana = \frac{\text{wartość na pozycji }\frac{n}{2} + \text{wartość na pozycji }(\frac{n}{2}+1)}{2}
Przykłady:
Nieparzyste n=7: pozycja = \frac{7+1}{2} = 4-ta wartość
Parzyste n=8: pozycje = \frac{8}{2} = 4-ta i 4+1 = 5-ta wartość
Moda (Dominanta)
Moda to najczęściej występująca wartość.
Przykład Ręcznego Obliczenia:
Używając zbioru danych: 2, 4, 4, 5, 5, 7, 9
Wartość
Częstość
2
1
4
2
5
2
7
1
9
1
Moda to 4 i 5 (rozkład bimodalny).
Obliczenie w R:
library(modeest)mfv(dane) # Najczęściej występująca wartość
[1] 4 5
Zalety:
Jedyna miara tendencji centralnej dla danych nominalnych
Może identyfikować wiele punktów szczytowych (dominujących) w danych
Wady:
Nie zawsze jednoznacznie zdefiniowana
Nie jest odpowiednia dla danych ciągłych
Średnia (arytmetyczna) Ważona (*)
Średnia ważona jest używana, gdy niektóre punkty danych są ważniejsze niż inne. Występują dwa typy średnich ważonych: z wagami nienormalizowanymi i z wagami znormalizowanymi.
Średnia Ważona z Wagami Nienormalizowanymi
Jest to standardowa forma średniej ważonej, gdzie wagi mogą być dowolnymi liczbami dodatnimi reprezentującymi ważność każdego punktu danych.
x <-c(2, 4, 5, 7)w <-c(1, 2, 3, 1)weighted.mean(x, w)
[1] 4.571429
Średnia Ważona z Wagami Znormalizowanymi (Ułamki)
W tym przypadku wagi są ułamkami sumującymi się do 1, reprezentującymi proporcję ważności dla każdego punktu danych.
Wzór:\bar{x}_w = \sum_{i=1}^n w_i x_i, gdzie \sum_{i=1}^n w_i = 1
Przykład Obliczeń Ręcznych:
Obliczmy średnią ważoną dla zbioru danych: 2, 4, 5, 7 z wagami znormalizowanymi 0.1, 0.3, 0.4, 0.2
Krok
Opis
Obliczenie
1
Pomnóż każdą wartość przez jej wagę
(2 * 0.1) + (4 * 0.3) + (5 * 0.4) + (7 * 0.2)
2
Zsumuj wyniki
0.2 + 1.2 + 2.0 + 1.4 = 4.8
Obliczenia w R:
x <-c(2, 4, 5, 7)w_normalized <-c(0.1, 0.3, 0.4, 0.2) # Uwaga: sumują się do 1sum(x * w_normalized)
[1] 4.8
Zalety Średnich Ważonych:
Uwzględniają różną ważność punktów danych
Wady Średnich Ważonych:
Wymagają uzasadnienia dla wag
Mogą być niewłaściwie wykorzystane w celu manipulacji wynikami
Mogą być mniej intuicyjne w interpretacji niż prosta średnia arytmetyczna
6.7 Miary Zmienności (Rozproszenia)
Te miary opisują, jak bardzo rozproszone są dane.
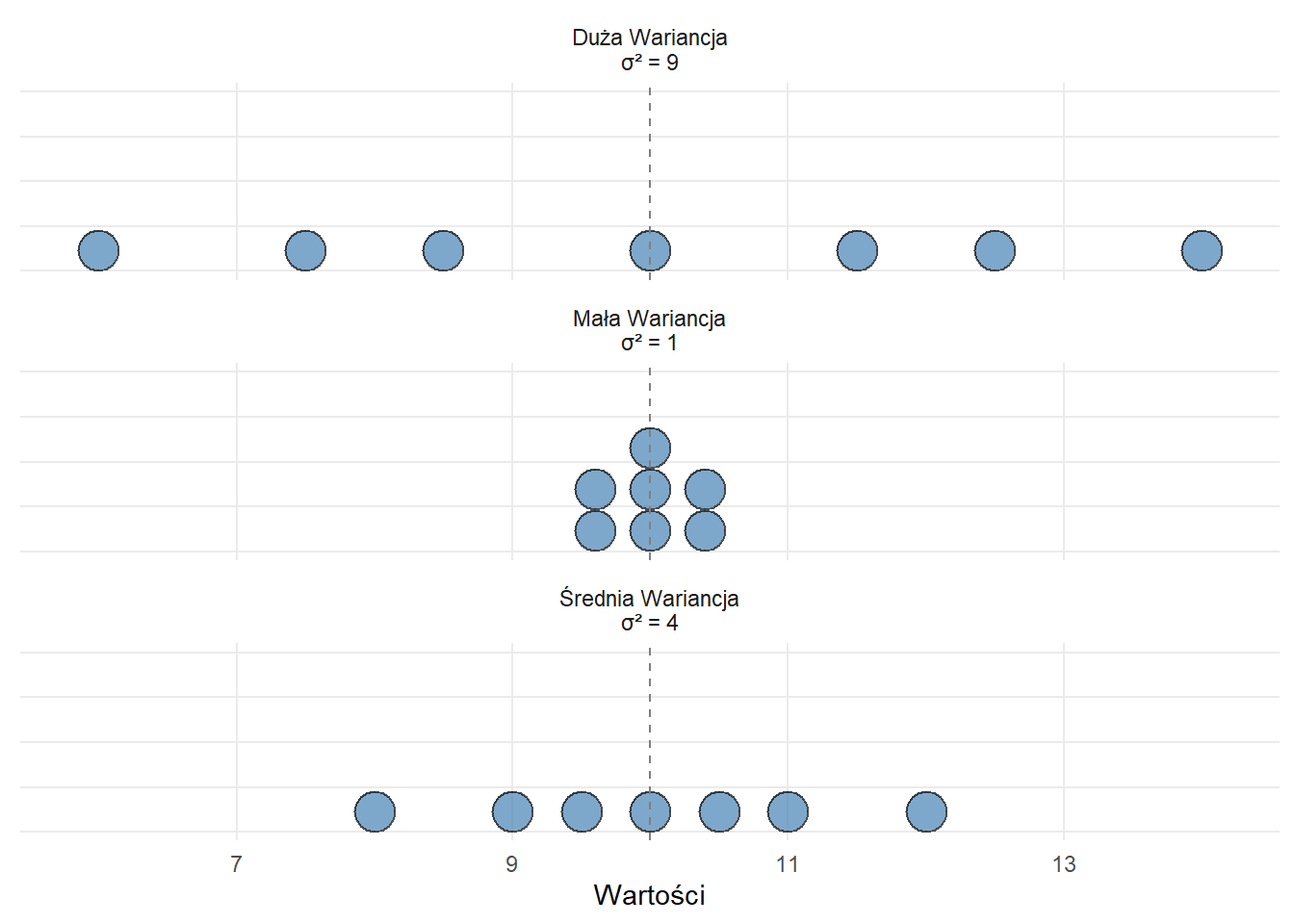
Zrozumienie Wariancji
Figure 6.1: Trzy wykresy punktowe pokazujące rosnącą wariancję przy stałej średniej
Powyższe trzy wykresy punktowe pokazują, w jaki sposób wariancja mierzy rozproszenie danych wokół wartości centralnej:
Wszystkie rozkłady mają tę samą średnią (μ = 10), oznaczoną linią przerywaną
Mała Wariancja (σ² = 1): Punkty są skupione blisko średniej
Średnia Wariancja (σ² = 4): Punkty wykazują umiarkowane rozproszenie
Duża Wariancja (σ² = 9): Punkty są szeroko rozproszone wokół średniej
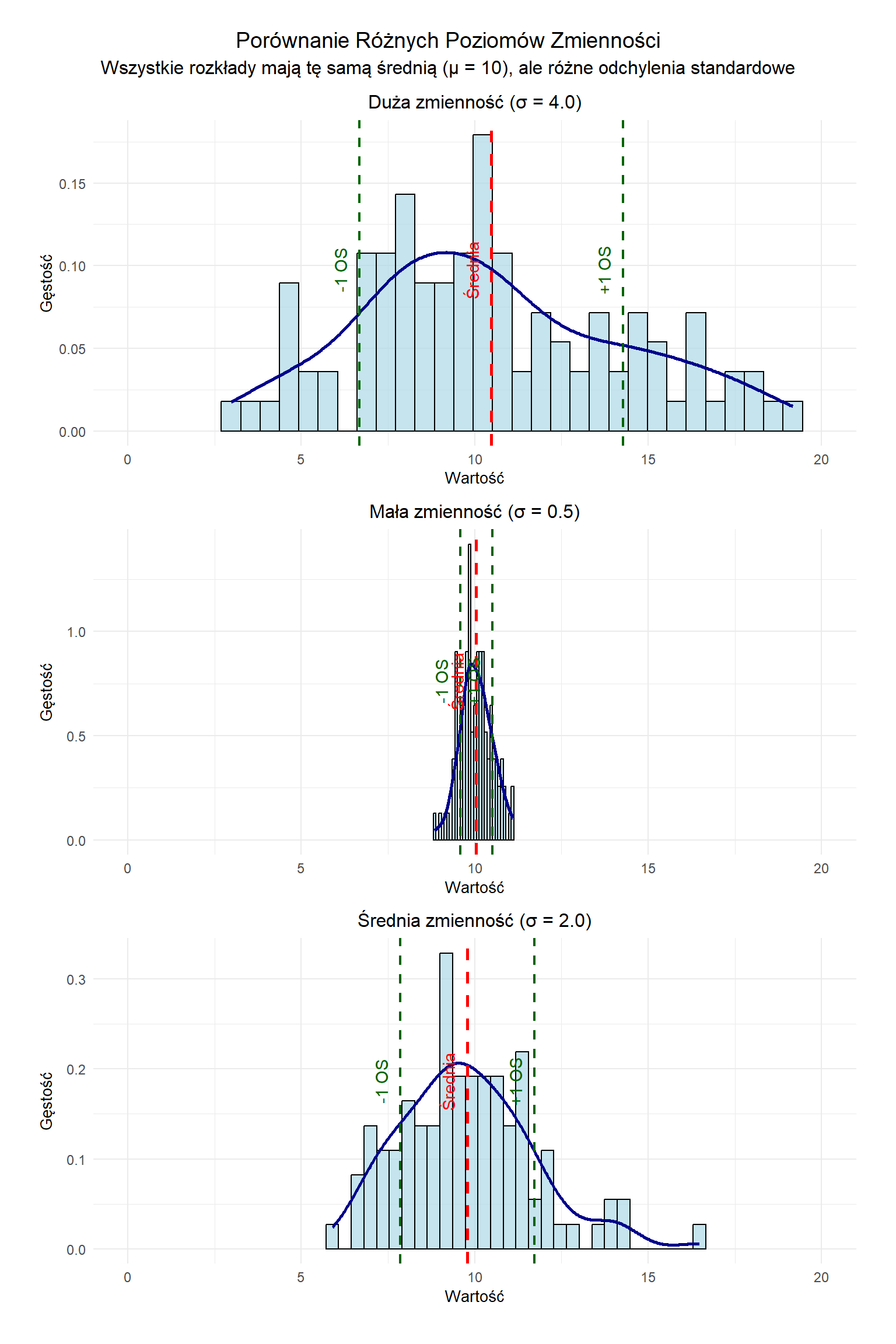
Różne Poziomy Zmienności
Ta wizualizacja przedstawia trzy rozkłady normalne o tej samej średniej (μ = 10), ale różnych poziomach zmienności:
Mała zmienność (σ = 0.5)
Punkty danych grupują się ściśle wokół średniej
Krzywa gęstości jest wysoka i wąska
Większość obserwacji mieści się w przedziale ±0.5 jednostki (odchylenia stand.) od średniej
Średnia zmienność (σ = 2.0)
Punkty danych są bardziej rozproszone wokół średniej
Krzywa gęstości jest niższa i szersza
Większość obserwacji mieści się w przedziale ±2 jednostki od średniej
Duża zmienność (σ = 4.0)
Punkty danych są szeroko rozproszone wokół średniej
Krzywa gęstości jest znacznie bardziej płaska i szeroka
Większość obserwacji mieści się w przedziale ±4 jednostki od średniej
Zwróć uwagę, jak odchylenie standardowe (σ) bezpośrednio powiązane jest z rozproszeniem rozkładu - większe wartości σ wskazują na większą zmienność danych, podczas gdy mniejsze wartości oznaczają, że punkty danych mają tendencję do grupowania się bliżej średniej.
Rozstęp
Rozstęp to różnica między wartością maksymalną a minimalną.
Wzór:R = x_{max} - x_{min}
Przykład Ręcznego Obliczenia:
Używając zbioru danych: 2, 4, 4, 5, 5, 7, 9
Krok
Opis
Obliczenie
1
Znajdź wartość maksymalną
9
2
Znajdź wartość minimalną
2
3
Odejmij minimum od maksimum
9 - 2 = 7
Obliczenie w R:
dane <-c(2, 4, 4, 5, 5, 7, 9)range(dane)
[1] 2 9
max(dane) -min(dane)
[1] 7
Zalety:
Prosty do obliczenia i zrozumienia
Szybka informacja o ogólnym rozproszeniu danych
Wady:
Bardzo wrażliwy na wartości odstające
Nie dostarcza informacji o rozkładzie między skrajnościami
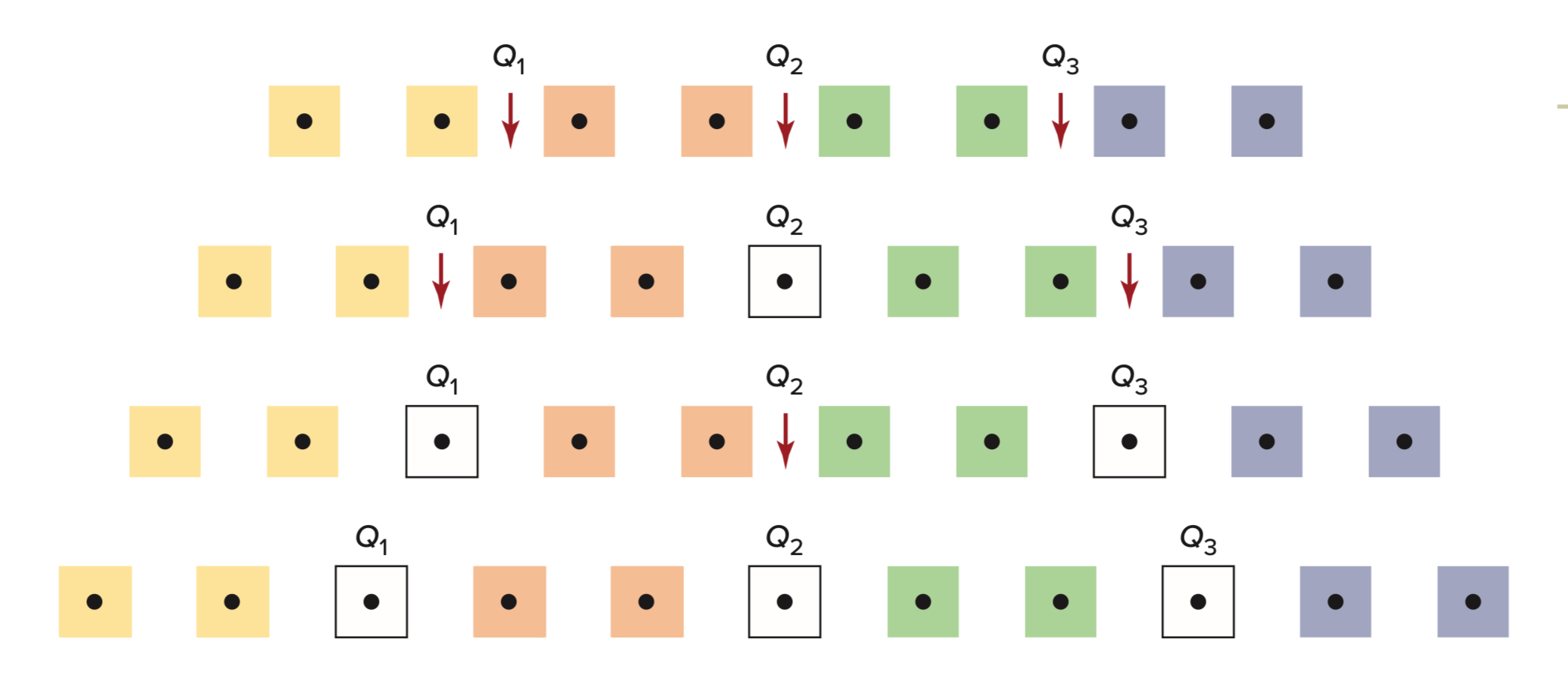
Rozstęp Międzykwartylowy (IQR)
IQR to różnica między 75. a 25. percentylem (3. a 1. kwartylem).
Wzór:IQR = Q_3 - Q_1
Aby znaleźć kwartyle ręcznie:
Dla nieparzystej liczby wartości:
Q2 (mediana) to środkowa wartość
Q1 to mediana dolnej połowy (wyłączając medianę dla wszystkich obserwacji)
Q3 to mediana górnej połowy (wyłączając medianę dla wszystkich obserwacji)
Dla parzystej liczby wartości:
Q2 to średnia z dwóch środkowych wartości
Q1 to mediana dolnej połowy (wyłączając medianę dla wszystkich obserwacji)
Q3 to mediana górnej połowy (wyłączając medianę dla wszystkich obserwacji)
Przykład Ręcznego Obliczenia:
Używając zbioru danych: 2, 4, 4, 5, 5, 7, 9
Krok
Opis
Obliczenie
1
Uporządkuj dane
2, 4, 4, 5, 5, 7, 9
2
Znajdź Q2 (medianę)
5
3
Znajdź Q1 (medianę dolnej połowy)
4
4
Znajdź Q3 (medianę górnej połowy)
7
5
Oblicz IQR
Q3 - Q1 = 7 - 4 = 3
Obliczenie w R:
dane <-c(2, 4, 4, 5, 5, 7, 9)print(dane)
[1] 2 4 4 5 5 7 9
quantile(dane, type =1)
0% 25% 50% 75% 100%
2 4 5 7 9
IQR(dane, type =1)
[1] 3
Zalety:
Odporny na wartości odstające
Dostarcza informacji o rozproszeniu środkowych 50% danych
Wady:
Ignoruje ogony rozkładu
Mniej efektywny niż odchylenie standardowe dla rozkładów normalnych
Wariancja
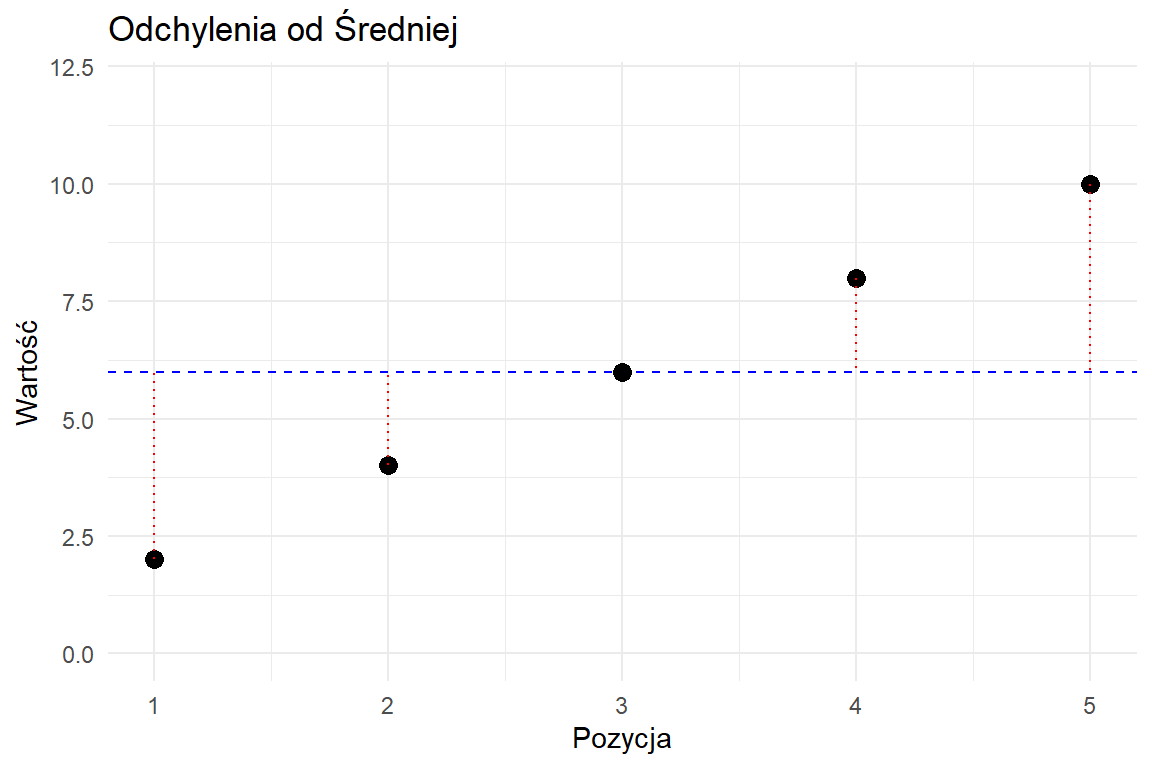
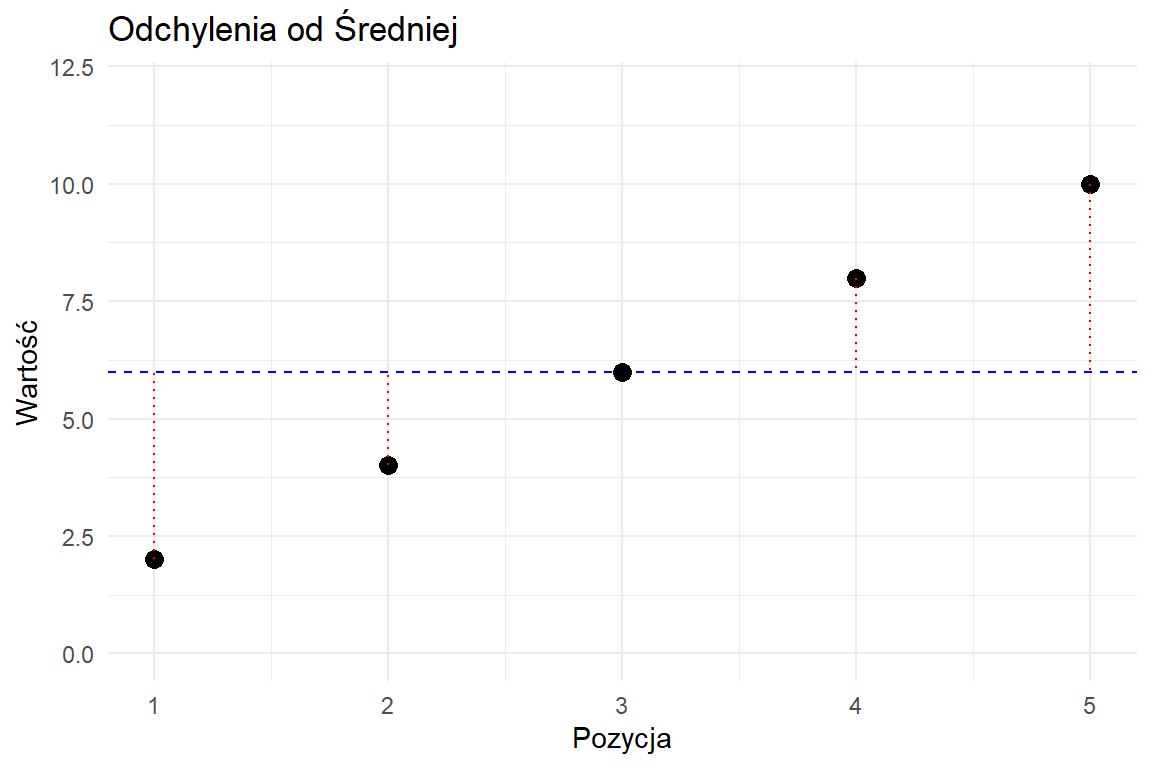
Wariancja mierzy średnie kwadratowe odchylenie od średniej.
Średnia służy jako punkt odniesienia (niebieska przerywana linia)
Odchylenia pokazują odległość od średniej (czerwone kropkowane linie)
Podniesienie do kwadratu sprawia, że wszystkie odchylenia są dodatnie (niebieskie słupki)
Większe odchylenia mają większy wpływ na wariancję
Przykład Ręcznego Obliczenia:
Używając zbioru danych: 2, 4, 4, 5, 5, 7, 9
Krok
Opis
Obliczenie
1
Oblicz średnią
\bar{x} = 5,14
2
Odejmij średnią od każdej obserwacji i podnieś wynik do kwadratu
(2 - 5,14)^2 = 9,86
(4 - 5,14)^2 = 1,30
(4 - 5,14)^2 = 1,30
(5 - 5,14)^2 = 0,02
(5 - 5,14)^2 = 0,02
(7 - 5,14)^2 = 3,46
(9 - 5,14)^2 = 14,90
3
Sumuj kwadraty różnic
30,86
4
Podziel przez (n-1), czyli przez liczbę obserwacji - 1
30,86 / 6 = 5,14
Obliczenie w R:
var(dane)
[1] 5.142857
Zalety:
Wykorzystuje wszystkie punkty danych
Podstawa dla wielu testów statystycznych*
Wady:
Jednostki są podniesione do kwadratu, co utrudnia interpretację
Wrażliwa na wartości odstające
Poprawka Bessela: Dlaczego Dzielimy przez (n-1), a nie po prostu przez n
Gdy obliczamy odchylenia od średniej, ich suma musi wynosić zero. To matematyczny fakt: \sum(x_i - \bar{x}) = 0
Pomyśl o tym Tak:
Jeśli masz 5 liczb i ich średnią:
Po obliczeniu 4 odchyleń od średniej
5-te odchylenie MUSI być takie, żeby suma była zero
Nie masz tak naprawdę 5 niezależnych odchyleń
Masz tylko 4 prawdziwie “swobodne” odchylenia
Prosty Przykład:
Liczby: 2, 4, 6, 8, 10
Średnia = 6
Odchylenia: -4, -2, 0, +2, +4
Zauważ, że sumują się do zera
Jeśli znasz dowolne 4 odchylenia, 5-te jest z góry określone!
Dlatego Właśnie:
Przy obliczaniu wariancji: s^2 = \frac{\sum(x_i - \bar{x})^2}{n-1}
Dzielimy przez (n-1), a nie n
Ponieważ tylko (n-1) odchyleń jest naprawdę niezależnych
Ostatnie jest określone przez pozostałe
Stopnie Swobody:
n = liczba obserwacji
1 = ograniczenie (odchylenia muszą sumować się do zera)
n-1 = stopnie swobody = liczba prawdziwie niezależnych odchyleń
Kiedy Stosować:
Przy obliczaniu wariancji z próby
Przy obliczaniu odchylenia standardowego z próby
Kiedy NIE Stosować:
W obliczeniach dla całej populacji (gdy mamy wszystkie dane)
Przy obliczaniu odchylenia od ustalonej, znanej wartości parametru populacji statystycznej
Pamiętaj:
To nie jest tylko statystyczny trik
Odchylenia od średniej muszą sumować się do zera
To ograniczenie kosztuje nas jeden stopień swobody
Odchylenie Standardowe
Odchylenie standardowe to pierwiastek kwadratowy z wariancji i mierzy przeciętne rozproszenie danych względem ich średniej arytmetycznej. W przeciwieństwie do wariancji, jest to miara mianowana i interpretowana w jednostkach bdanej zmiennej.
Musimy przejść 0.6 drogi między 85 a 88 P_{60} = 85 + 0.6(88-85)P_{60} = 85 + 0.6(3)P_{60} = 85 + 1.8 = 86.8
Co to oznacza: 60% uczniów uzyskało wynik 86.8 lub niższy.
Rangi Percentylowe (RP) (*)
Czym jest Ranga Percentylowa?
Percentyle i rangi percentylowe to powiązane, ale przeciwstawne pojęcia:
Kluczowa różnica: - Percentyl → “Jaki wynik znajduje się na 75. percentylu?” (pozycja → wartość) - Ranga Percentylowa → “Jaką rangę percentylową ma wynik 75?” (wartość → pozycja)
Ranga percentylowa informuje nas, jaki procent wartości znajduje się poniżej określonego wyniku. Można o tym myśleć jako o odpowiedzi na pytanie: “Ile procent klasy uzyskało wynik gorszy ode mnie?”
Wzór
RP = \frac{\text{liczba wartości poniżej} + 0{,}5 \times \text{liczba wartości równych}}{\text{całkowita liczba wartości}} \times 100
Przykład 4: Wyznaczanie Rangi Percentylowej
Rozważmy następujące wyniki egzaminu (posortowane):
Pozycja
1
2
3
4
5
6
7
8
9
10
Wynik
65
70
70
75
75
75
80
85
85
90
Wyznaczmy RP dla wyniku 75 (wyróżnionego).
Krok 1: Dokładne policzenie - Wartości poniżej 75: 65, 70, 70 → 3 wartości - Wartości równe 75: 75, 75, 75 → 3 wartości - Wszystkie wartości: 10
Interpretacja: Wynik 75 jest wyższy niż 45% wyników w klasie.
Sprawdzenie poprawności: To ma sens! Jest 3 wyniki wyraźnie poniżej 75, a Ty jesteś w środku grupy 3 osób, które uzyskały 75, więc jesteś mniej więcej na pozycji 4,5 z 10 = 45%. ✓
Zrozumienie Współczynnika 0,5
P: Dlaczego mnożymy wartości równe przez 0,5?
O: Współczynnik 0,5 oznacza, że liczymy połowę wartości remisowych jako znajdujące się poniżej nas.
Oto intuicja: Jeśli uzyskałeś wynik 75 wraz z dwiema innymi osobami, czy powinieneś uznać się za: - Lepszego od wszystkich z nich? (To nie byłoby sprawiedliwe wobec nich) - Gorszego od wszystkich z nich? (To nie byłoby sprawiedliwe wobec ciebie) - Gdzieś pośrodku? ✓ (To najsprawiedliwsze podejście)
Używając naszego przykładu: - 3 osoby uzyskały wynik poniżej 75: liczymy wszystkie 3 - 3 osoby uzyskały dokładnie 75 (łącznie z tobą): liczymy połowę z nich = 0,5 × 3 = 1,5 - Razem poniżej lub remis: 3 + 1,5 = 4,5 z 10 = 45%
Używając 0,5, mówimy zasadniczo: “Spośród osób, które zremisowały ze mną, mogę założyć, że wypadłem lepiej niż połowa z nich.” To traktuje wszystkich z tym samym wynikiem równo i unika dawania komukolwiek niesprawiedliwej przewagi.
Zadanie do Samodzielnego Rozwiązania
Używając tego samego zestawu danych powyżej, wyznacz rangę percentylową dla wyniku 85.
Kliknij, aby zobaczyć rozwiązanie
Liczenie: - Wartości poniżej 85: 65, 70, 70, 75, 75, 75, 80 → 7 wartości - Wartości równe 85: 85, 85 → 2 wartości - Wszystkie: 10 wartości
Różne pakiety oprogramowania mogą używać nieco innych metod obliczania rang percentylowych: - R: Funkcja ecdf() lub obliczenia ręczne - Python (pandas): Metoda rank(pct=True)
Mogą one dawać nieco różne wyniki w zależności od sposobu obsługi wartości remisowych i przypadków brzegowych.
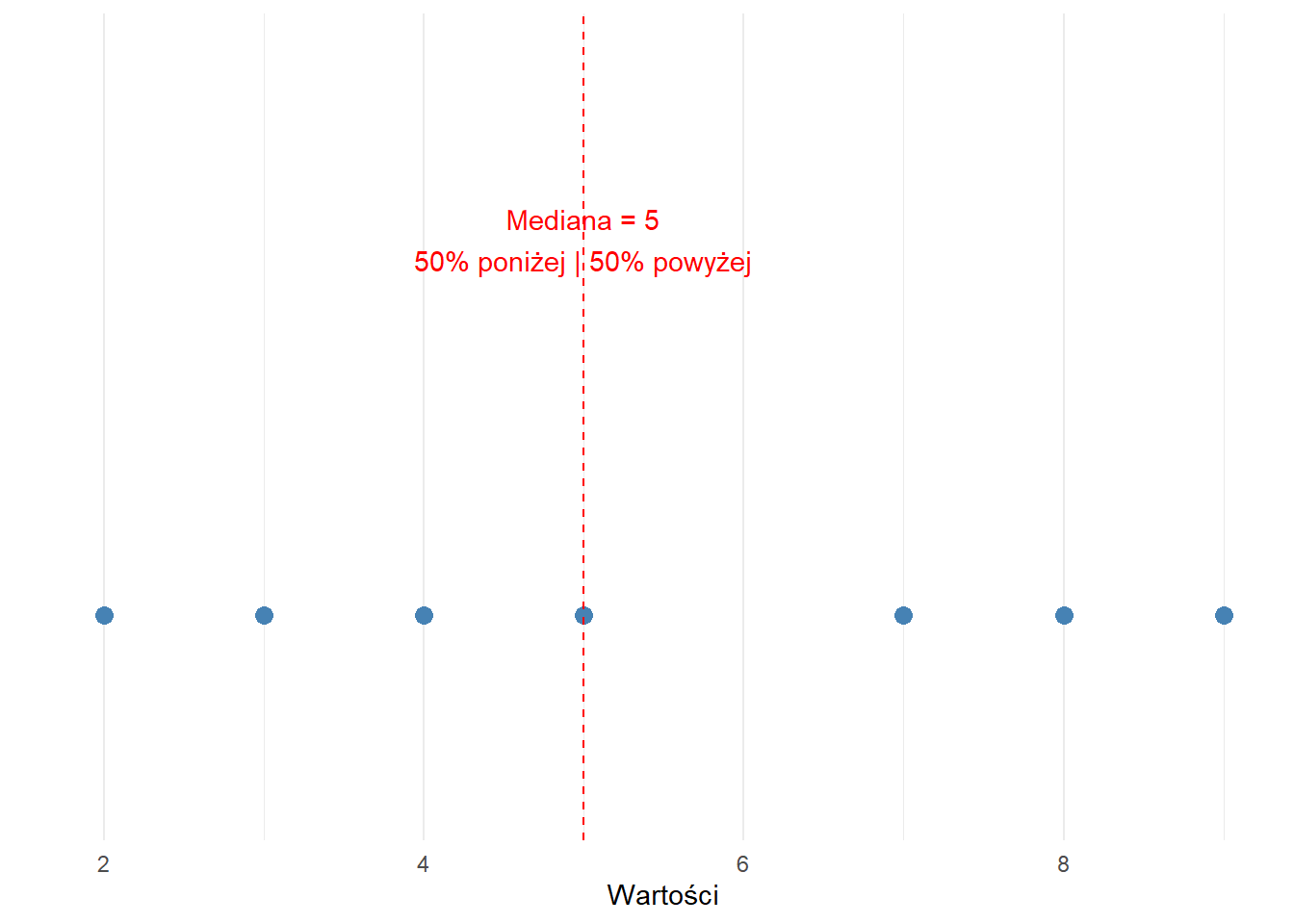
Podwójna Funkcja Mediany
Figure 6.2: Wizualizacja podwójnej roli mediany
Mediana pełni dwie odrębne, ale powiązane ze sobą role:
A. Jako Miara Centrum:
Reprezentuje środkowy punkt danych
Równoważy liczbę obserwacji po obu stronach
Jest odporna na wartości odstające (w przeciwieństwie do średniej arytmetycznej)
B. Jako Miara Pozycji Względnej:
Wyznacza 50-ty percentyl
Dzieli dane na dwie równe części
Każdą wartość można do niej odnieść:
Poniżej mediany: dolne 50%
Powyżej mediany: górne 50%
Ta podwójna natura sprawia, że mediana jest szczególnie przydatna do:
Opisywania wartości typowych (tendencja centralna)
Zrozumienia pozycji w rozkładzie (pozycja względna)
Dokonywania porównań między różnymi zbiorami danych
Wykres pudełkowy
Wykresy pudełkowe (znane również jako wykresy skrzynkowe lub box-and-whisker plots) są użytecznymi narzędziami wizualizacji rozkładów danych.
Konstrukcja wykresu pudełkowego Tukeya
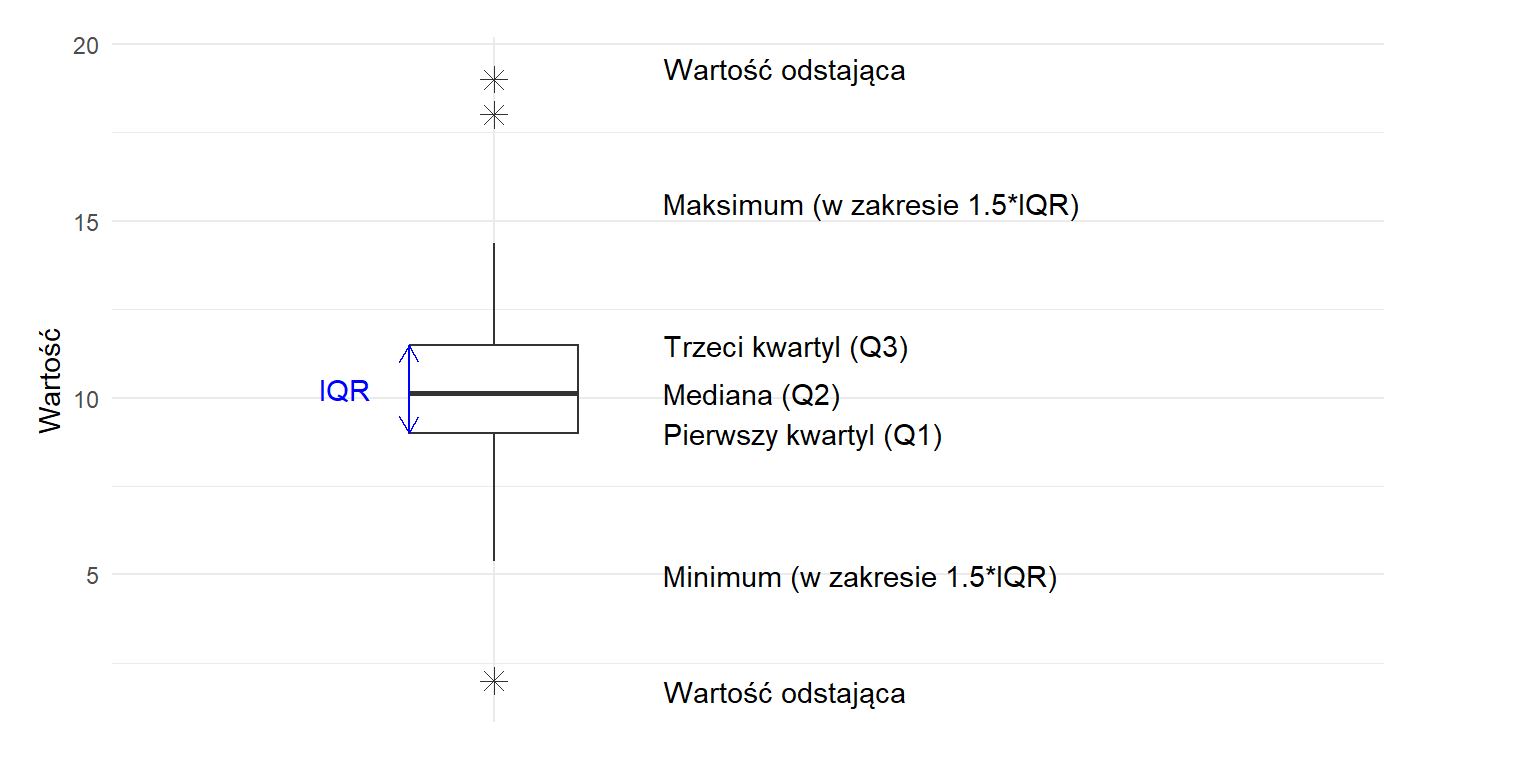
Wykres pudełkowy został wprowadzony przez Johna Tukeya jako część jego zestawu narzędzi eksploracyjnej analizy danych. Wykres wizualizuje rozkład danych na podstawie pięciu podstawowych statystyk.
Podsumowanie pięciu liczb
Wykres pudełkowy reprezentuje pięć kluczowych wartości statystycznych:
Minimum: Najmniejsza wartość w zbiorze danych (z wyłączeniem wartości odstających)
Pierwszy kwartyl (Q1): 25. percentyl, poniżej którego znajduje się 25% obserwacji
Mediana (Q2): 50. percentyl, który dzieli zbiór danych na dwie równe połowy
Trzeci kwartyl (Q3): 75. percentyl, poniżej którego znajduje się 75% obserwacji
Maksimum: Największa wartość w zbiorze danych (z wyłączeniem wartości odstających)
Komponenty wykresu pudełkowego
Figure 6.3: Diagram wykresu pudełkowego pokazujący jego kluczowe komponenty.
Komponenty wykresu pudełkowego obejmują:
Pudełko:
Reprezentuje rozstęp międzykwartylowy (IQR), zawierający środkowe 50% danych
Dolna krawędź reprezentuje Q1
Górna krawędź reprezentuje Q3
Linia wewnątrz pudełka reprezentuje medianę (Q2)
Wąsy:
Rozciągają się od pudełka, aby pokazać zakres danych niebędących wartościami odstającymi
W wykresie pudełkowym Tukeya wąsy rozciągają się do 1,5 × IQR od krawędzi pudełka:
Dolny wąs: rozciąga się do minimalnej wartości ≥ (Q1 - 1,5 × IQR)
Górny wąs: rozciąga się do maksymalnej wartości ≤ (Q3 + 1,5 × IQR)
Wartości odstające:
Punkty, które wykraczają poza wąsy
Indywidualnie zaznaczone jako kropki lub inne symbole
Wartości, które są < (Q1 - 1,5 × IQR) lub > (Q3 + 1,5 × IQR)
Kluczowe cechy do obserwacji
Interpretując wykresy pudełkowe, zwróć uwagę na następujące cechy:
Tendencja centralna: Położenie linii mediany wewnątrz pudełka
Rozproszenie: Szerokość pudełka (IQR) i długość wąsów
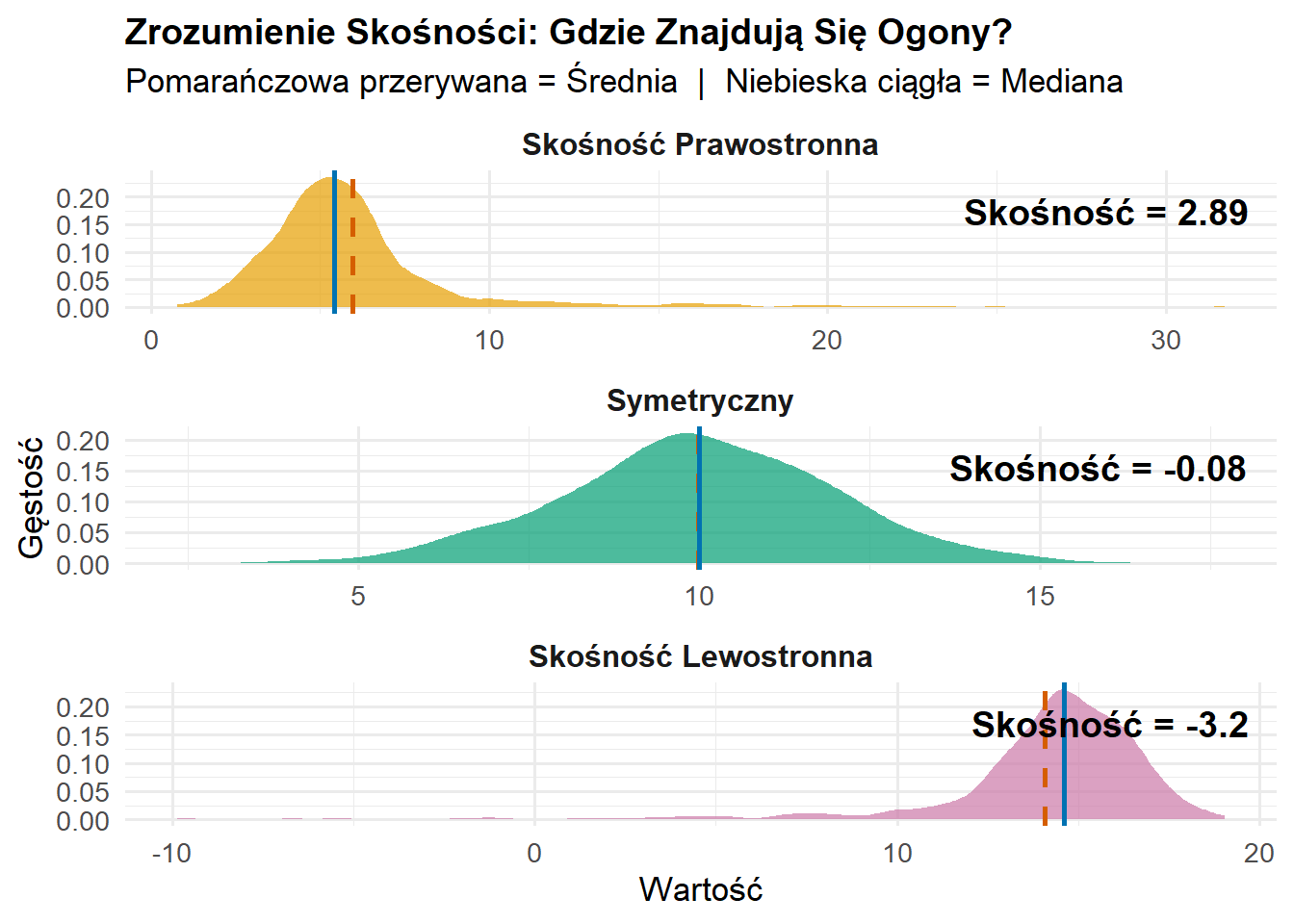
Skośność:
Dane symetryczne: mediana znajduje się w przybliżeniu na środku pudełka, wąsy mają podobną długość
Skośność prawostronna (dodatnia): mediana jest bliżej dolnej części pudełka, górny wąs jest dłuższy
Skośność lewostronna (ujemna): mediana jest bliżej górnej części pudełka, dolny wąs jest dłuższy
Wartości odstające: Obecność pojedynczych punktów poza wąsami
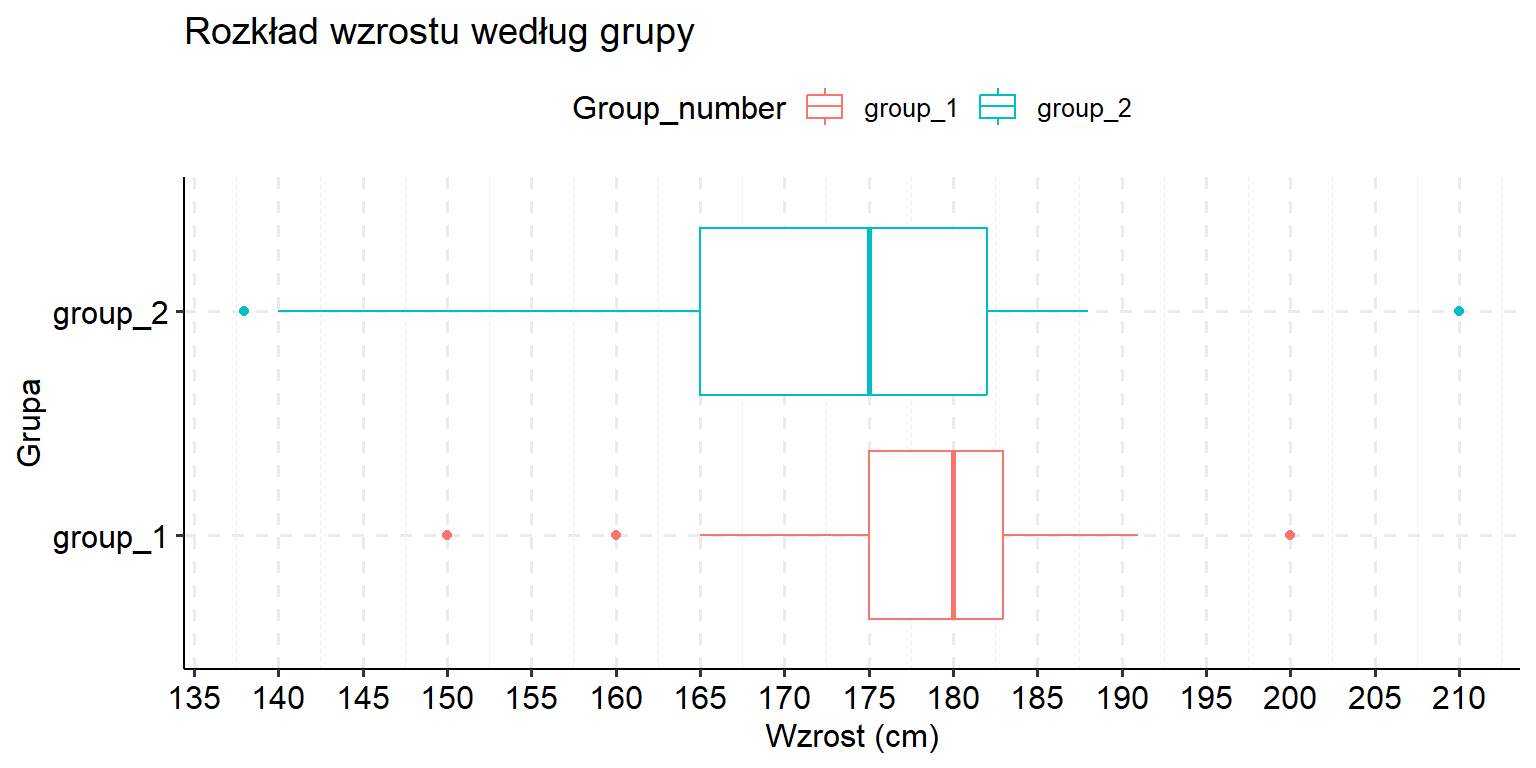
Studium przypadku: Porównanie wzrostu między grupami
Zastosujmy nasze zrozumienie wykresów pudełkowych do rzeczywistego zbioru danych. Mamy pomiary wzrostu (w centymetrach) z dwóch grup, każda po 25 studentów.
Warning: The `size` argument of `element_line()` is deprecated as of ggplot2 3.4.0.
ℹ Please use the `linewidth` argument instead.
ℹ The deprecated feature was likely used in the ggpubr package.
Please report the issue at <https://github.com/kassambara/ggpubr/issues>.
Warning: The `size` argument of `element_rect()` is deprecated as of ggplot2 3.4.0.
ℹ Please use the `linewidth` argument instead.
ℹ The deprecated feature was likely used in the ggpubr package.
Please report the issue at <https://github.com/kassambara/ggpubr/issues>.
Figure 6.4: Wykresy pudełkowe porównujące rozkłady wzrostu między grupami.
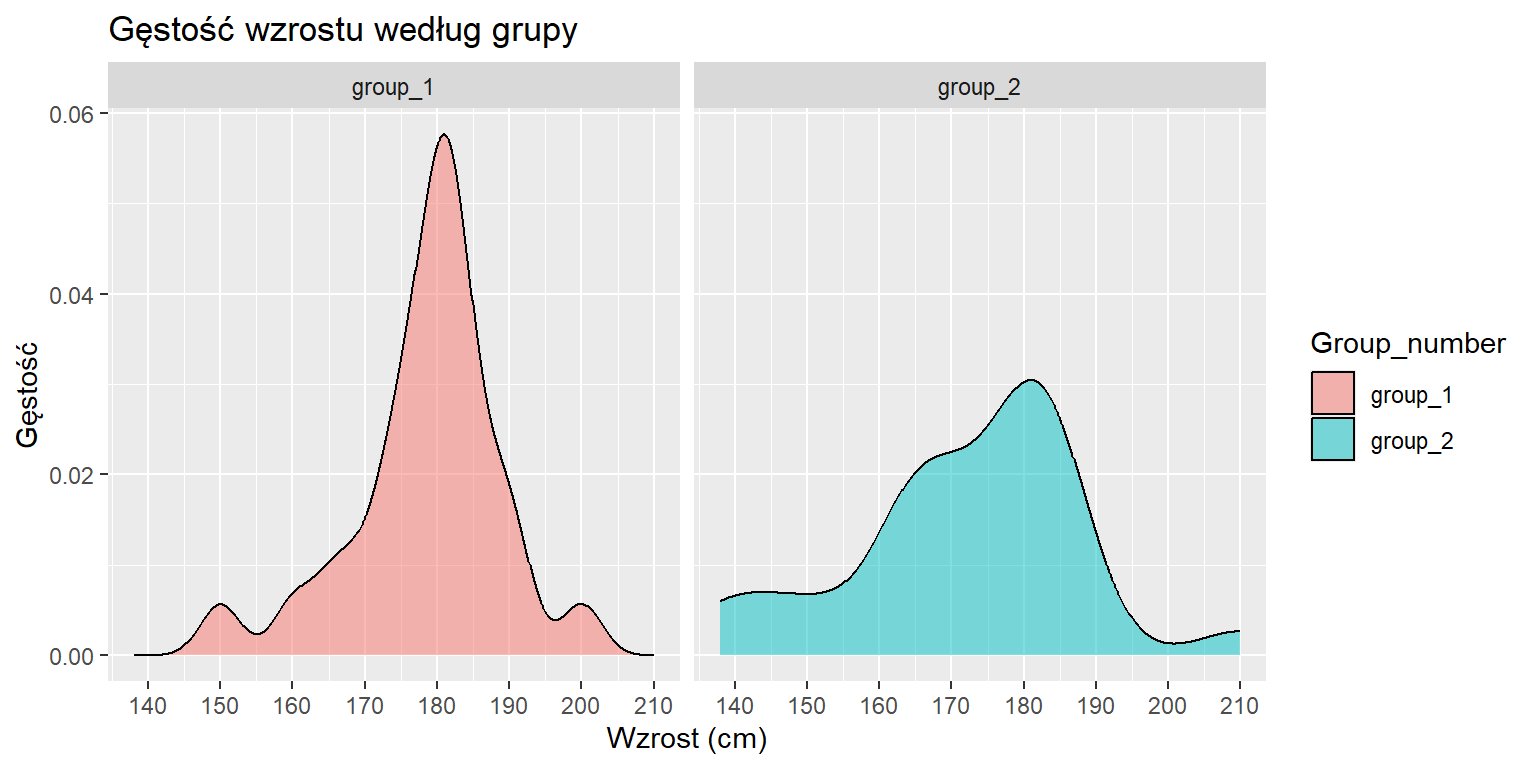
Aby uzupełnić nasze wykresy pudełkowe, przyjrzyjmy się również rozkładom gęstości:
# Tworzenie wykresów gęstościggplot(data = data_height_l) +geom_density(aes(x = height, fill = Group_number), alpha =0.5) +facet_grid(~ Group_number) +scale_x_continuous(breaks =seq(130, 210, 10)) +labs(title ="Gęstość wzrostu według grupy",x ="Wzrost (cm)",y ="Gęstość")
Figure 6.5: Wykresy gęstości pokazujące rozkłady wzrostu dla każdej grupy.
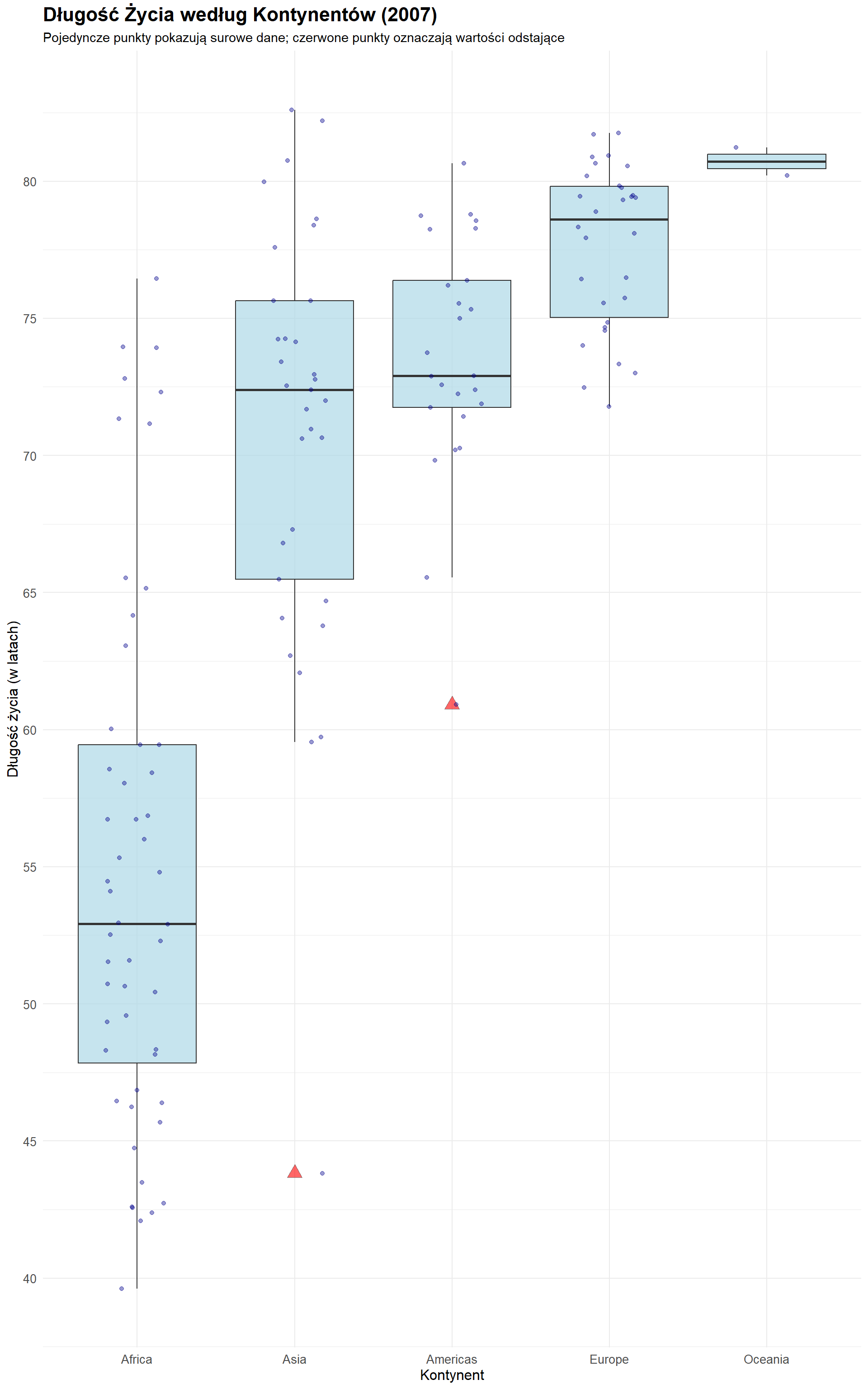
Ćwiczenie z interpretacji wykresów pudełkowych
Na podstawie powyższych wykresów pudełkowych i wykresów gęstości określ, czy każde z poniższych stwierdzeń jest Prawdziwe czy Fałszywe. Dla każdego stwierdzenia podaj krótkie wyjaśnienie oparte na dowodach z wizualizacji.
Pytania ćwiczeniowe
Studenci z grupy 2 (G2) w badanej próbie są, średnio, wyżsi niż ci z grupy 1 (G1).
Wzrost w grupie 1 (G1) jest bardziej rozproszony/rozłożony niż w grupie 2 (G2).
Najniższa osoba jest w grupie 2 (G2).
Oba zbiory danych mają skośność ujemną (lewostronną).
Połowa studentów w grupie 2 (G2) ma wzrost co najmniej 175 cm.
Wskazówki do interpretacji
Odpowiadając na te pytania, weź pod uwagę:
Pozycję linii mediany w każdym pudełku
Względne rozmiary pudełek (IQR)
Pozycje wartości minimalnych i maksymalnych
Symetrię rozkładów (zrównoważone czy z skośnością)
Długości wąsów
Dla każdego stwierdzenia ustal, czy jest Prawdziwe czy Fałszywe i podaj swoje wyjaśnienie:
Szablon odpowiedzi
Studenci z G2 są, średnio, wyżsi niż z G1: [Prawda/Fałsz]
Wyjaśnienie:
Wzrost G1 jest bardziej rozproszony/rozłożony: [Prawda/Fałsz]
Wyjaśnienie:
Najniższa osoba jest w G2: [Prawda/Fałsz]
Wyjaśnienie:
Oba zbiory danych mają skośność ujemną (lewostronną): [Prawda/Fałsz]
Wyjaśnienie:
Połowa G2 ma wzrost co najmniej 175 cm: [Prawda/Fałsz]
Wyjaśnienie:
Przeanalizujmy odpowiedzi na nasze pytania dotyczące interpretacji wykresów pudełkowych:
Rozwiązania
Studenci z G2 są, średnio, wyżsi niż z G1: Fałsz
Wyjaśnienie: Mediana wzrostu (środkowa linia w wykresie pudełkowym) dla G1 jest wyższa niż dla G2.
Wzrost G1 jest bardziej rozproszony/rozłożony: Fałsz
Wyjaśnienie: G2 wykazuje większe rozproszenie. Jest to widoczne na wykresie pudełkowym, gdzie G2 ma większy rozstęp międzykwartylowy (IQR) wynoszący 17,5 cm w porównaniu z 9,5 cm dla G1. G2 ma również szerszy zakres od wartości minimalnej do maksymalnej.
Najniższa osoba jest w G2: Prawda
Wyjaśnienie: Wartość minimalna w G2 wynosi 138 cm, co jest niższe niż wartość minimalna w G1 (150 cm).
Oba zbiory danych mają skośność ujemną (lewostronną): Prawda
Wyjaśnienie: W obu grupach linia mediany jest umieszczona w kierunku górnej części pudełka, a dolny wąs jest dłuższy niż górny. Wskazuje to na dłuższy ogon po lewej stronie rozkładu, co oznacza skośność ujemną.
Połowa G2 ma wzrost co najmniej 175 cm: Prawda
Wyjaśnienie: Mediana (środkowa linia w wykresie pudełkowym) dla G2 wynosi 175 cm, co oznacza, że 50% wartości jest większych lub równych 175 cm.
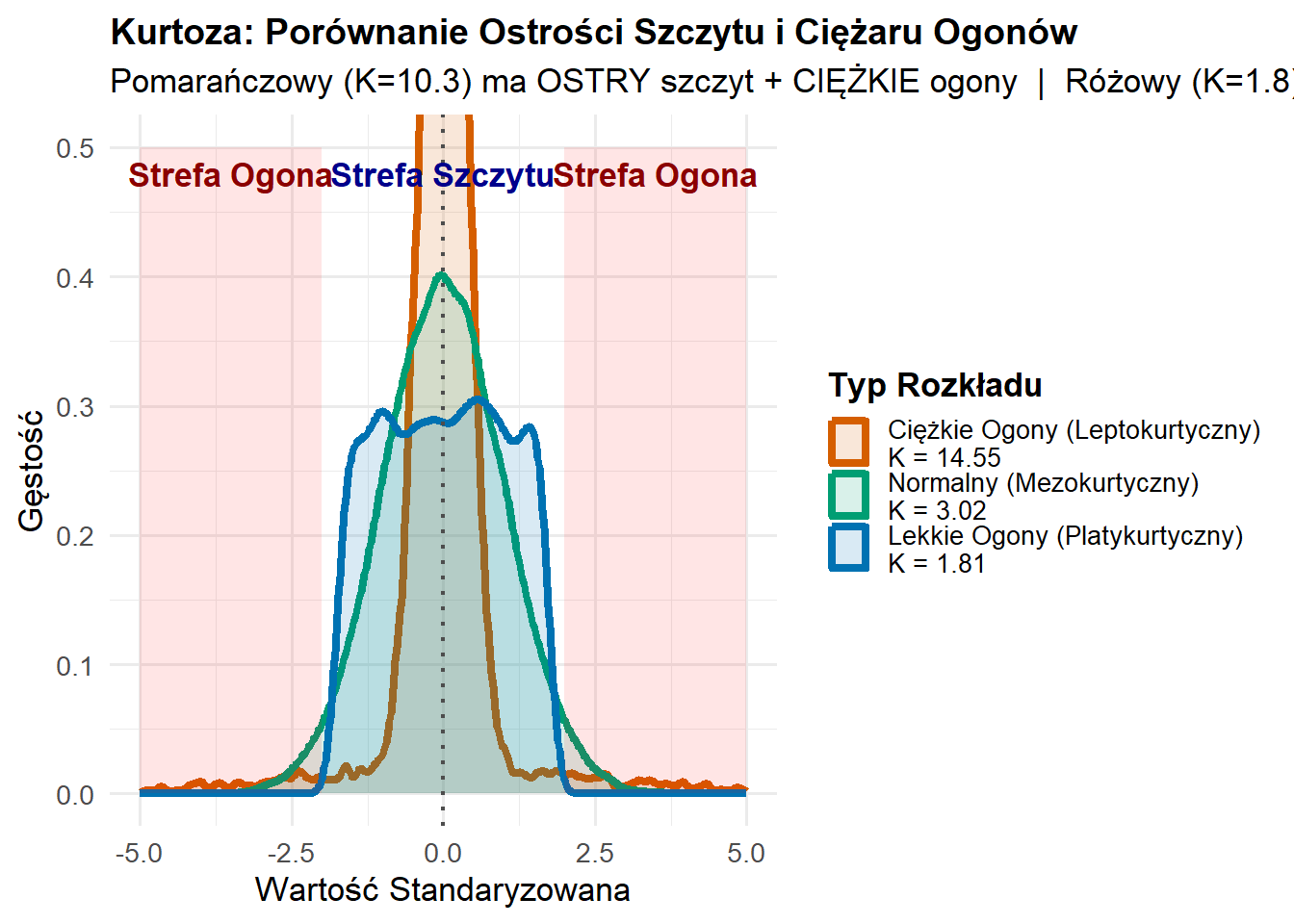
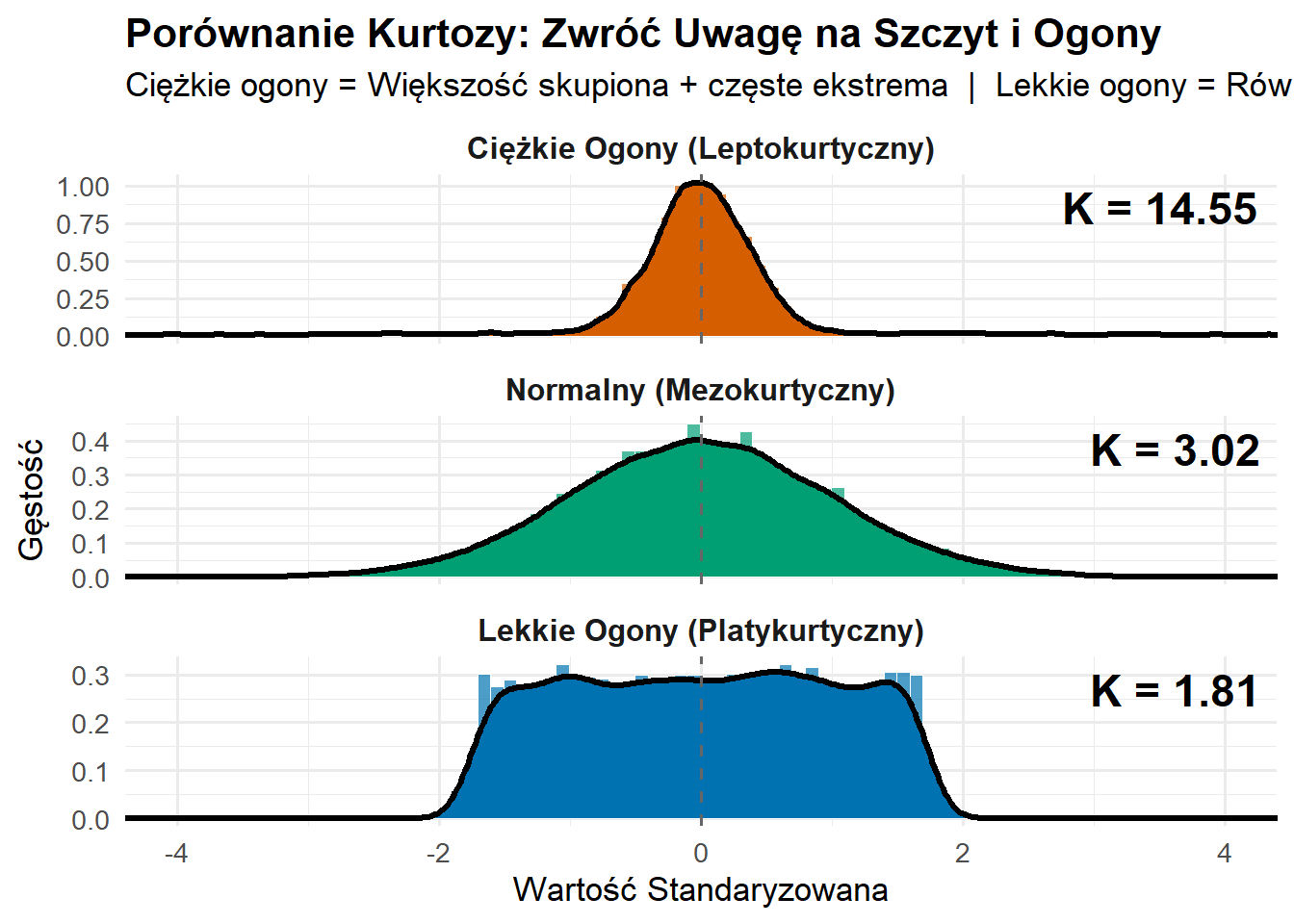
Co mierzy: “Ciężkość ogonów” rozkładu. Można to rozumieć jako odpowiedź na pytanie “jak ekstremalne są wartości ekstremalne?”
Wzór:
K = \frac{n(n+1)}{(n-1)(n-2)(n-3)} \sum_{i=1}^n \left(\frac{x_i - \bar{x}}{s}\right)^4 - \frac{3(n-1)^2}{(n-2)(n-3)}
Szybka interpretacja:
K > 3 (Leptokurtyczny): Ciężkie ogony, ostry szczyt (więcej wartości ekstremalnych)
K < 3 (Platykurtyczny): Lekkie ogony, płaski szczyt (mniej wartości ekstremalnych)
K ≈ 3 (Mezokurtyczny): Zachowanie podobne do rozkładu normalnego
Wizualizacja Kurtozy
set.seed(789)# Generowanie BARDZO wyraźnych przykładów - wszystkie wyśrodkowane w 0 z odch. stand. ≈ 1n <-8000# EKSTREMALNE ciężkie ogony: mieszanka ciasnego centrum + ekstremalne wartości odstająceciezkie_ogony <-c(rnorm(7000, 0, 0.5), # Bardzo ciasne centrum (ostry szczyt)rnorm(1000, 0, 4)) # Wiele ekstremalnych wartości# Lekkie ogony: rozkład jednostajny (brak możliwych wartości odstających)lekkie_ogony <-runif(n, -1.73, 1.73) # Przeskalowane do odch. stand. ≈ 1# Normalny: rozkład referencyjnynormalne_ogony <-rnorm(n, 0, 1)# Standaryzacja wszystkich do tej samej skaliciezkie_ogony <-scale(ciezkie_ogony)[,1]lekkie_ogony <-scale(lekkie_ogony)[,1]normalne_ogony <-scale(normalne_ogony)[,1]df_kurtoza <-tibble(wartosc =c(ciezkie_ogony, lekkie_ogony, normalne_ogony),typ =factor(rep(c("Ciężkie Ogony (Leptokurtyczny)", "Lekkie Ogony (Platykurtyczny)", "Normalny (Mezokurtyczny)"),each = n),levels =c("Ciężkie Ogony (Leptokurtyczny)","Normalny (Mezokurtyczny)","Lekkie Ogony (Platykurtyczny)"))) %>%filter(wartosc >=-5& wartosc <=5)# Obliczanie kurtozystatystyki_kurtoza <- df_kurtoza %>%group_by(typ) %>%summarise(k =round(kurtosis(wartosc), 2))# Nakładające się wykresy gęstości - najlepiej pokazują zachowanie ogonówggplot(df_kurtoza, aes(x = wartosc, color = typ, fill = typ)) +geom_density(alpha =0.15, linewidth =1.5) +geom_vline(xintercept =0, linetype ="dotted", color ="gray30", linewidth =0.8) +annotate("rect", xmin =-5, xmax =-2, ymin =0, ymax =0.5,alpha =0.1, fill ="red") +annotate("rect", xmin =2, xmax =5, ymin =0, ymax =0.5,alpha =0.1, fill ="red") +annotate("text", x =-3.5, y =0.48, label ="Strefa Ogona",color ="darkred", fontface ="bold", size =4.5) +annotate("text", x =3.5, y =0.48, label ="Strefa Ogona",color ="darkred", fontface ="bold", size =4.5) +annotate("text", x =0, y =0.48, label ="Strefa Szczytu",color ="darkblue", fontface ="bold", size =4.5) +scale_color_manual(values =c("#D55E00", "#009E73", "#0072B2"),labels =function(x) { k_val <- statystyki_kurtoza$k[match(x, statystyki_kurtoza$typ)]paste0(x, "\nK = ", k_val) } ) +scale_fill_manual(values =c("#D55E00", "#009E73", "#0072B2"),labels =function(x) { k_val <- statystyki_kurtoza$k[match(x, statystyki_kurtoza$typ)]paste0(x, "\nK = ", k_val) } ) +coord_cartesian(ylim =c(0, 0.5)) +labs(title ="Kurtoza: Porównanie Ostrości Szczytu i Ciężaru Ogonów",subtitle ="Pomarańczowy (K=10.3) ma OSTRY szczyt + CIĘŻKIE ogony | Różowy (K=1.8) jest PŁASKI wszędzie",x ="Wartość Standaryzowana",y ="Gęstość",color ="Typ Rozkładu",fill ="Typ Rozkładu" ) +theme_minimal(base_size =13) +theme(legend.position ="right",legend.text =element_text(size =10),legend.title =element_text(face ="bold"),plot.title =element_text(face ="bold", size =14) )
# Widok panelowy koncentrujący się na różnicachggplot(df_kurtoza, aes(x = wartosc, fill = typ)) +geom_histogram(aes(y =after_stat(density)), bins =100, alpha =0.7, color ="white", linewidth =0.1) +geom_density(linewidth =1.2, color ="black") +geom_vline(xintercept =0, linetype ="dashed", color ="gray40") +geom_text(data = statystyki_kurtoza,aes(x =Inf, y =Inf, label =paste("K =", k)),hjust =1.1, vjust =1.5, size =6, fontface ="bold") +facet_wrap(~typ, ncol =1, scales ="free_y") +scale_fill_manual(values =c("#D55E00", "#009E73", "#0072B2")) +coord_cartesian(xlim =c(-4, 4)) +labs(title ="Porównanie Kurtozy: Zwróć Uwagę na Szczyt i Ogony",subtitle ="Ciężkie ogony = Większość skupiona + częste ekstrema | Lekkie ogony = Równomiernie rozłożone, bez ekstremów",x ="Wartość Standaryzowana",y ="Gęstość" ) +theme_minimal(base_size =13) +theme(legend.position ="none",strip.text =element_text(face ="bold", size =12),plot.title =element_text(face ="bold") )
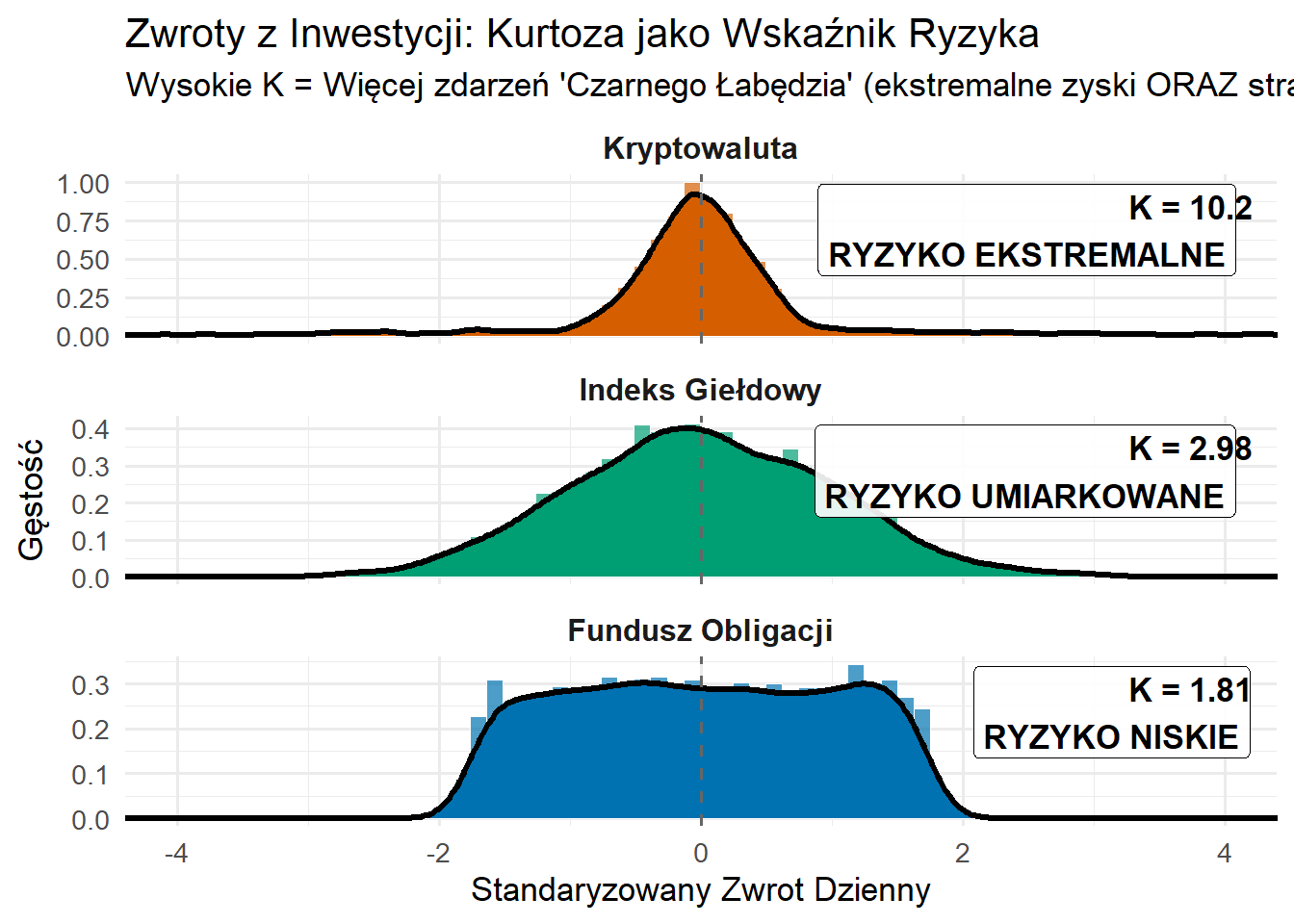
Przykład Zastosowania: Stopy Zwrotu z Inwestycji
set.seed(101)# Symulacja dziennych stóp zwrotu z BARDZO różną kurtoząliczba_dni <-3000# Zmienna kryptowaluta: ekstremalne ruchy (krachy i wzrosty)# Większość dni normalna, ale częste ekstremalne zdarzeniazwroty_krypto <-c(rnorm(2400, 0, 0.8), # 80% normalnych dnirnorm(600, 0, 5)) # 20% dni ekstremalnej zmienności# Stabilne obligacje: bardzo konsekwentne, ograniczone zwroty (bez niespodzianek)zwroty_obligacje <-runif(liczba_dni, -1.2, 1.2)# Fundusz indeksowy: typowe zachowanie rynkowezwroty_indeks <-rnorm(liczba_dni, 0, 1)# Standaryzacja dla porównaniazwroty_krypto <-scale(zwroty_krypto)[,1]zwroty_obligacje <-scale(zwroty_obligacje)[,1]zwroty_indeks <-scale(zwroty_indeks)[,1]df_zwroty <-tibble(zwrot =c(zwroty_krypto, zwroty_obligacje, zwroty_indeks),inwestycja =factor(rep(c("Kryptowaluta", "Fundusz Obligacji", "Indeks Giełdowy"),each = liczba_dni),levels =c("Kryptowaluta","Indeks Giełdowy","Fundusz Obligacji"))) %>%filter(zwrot >=-5& zwrot <=5)# Obliczanie kurtozystatystyki_zwroty <- df_zwroty %>%group_by(inwestycja) %>%summarise(k =round(kurtosis(zwrot), 2),poziom_ryzyka =case_when( k >5~"RYZYKO EKSTREMALNE", k >3.5~"RYZYKO WYSOKIE", k >2.5~"RYZYKO UMIARKOWANE",TRUE~"RYZYKO NISKIE" ) )ggplot(df_zwroty, aes(x = zwrot, fill = inwestycja)) +geom_histogram(aes(y =after_stat(density)), bins =80, alpha =0.7, color ="white", linewidth =0.1) +geom_density(linewidth =1.2, color ="black") +geom_vline(xintercept =0, linetype ="dashed", color ="gray40") +geom_label(data = statystyki_zwroty,aes(x =Inf, y =Inf, label =paste0("K = ", k, "\n", poziom_ryzyka)),hjust =1.1, vjust =1.1, size =4.5, fontface ="bold",fill ="white", alpha =0.9) +facet_wrap(~inwestycja, ncol =1, scales ="free_y") +scale_fill_manual(values =c("#D55E00", "#009E73", "#0072B2")) +coord_cartesian(xlim =c(-4, 4)) +labs(title ="Zwroty z Inwestycji: Kurtoza jako Wskaźnik Ryzyka",subtitle ="Wysokie K = Więcej zdarzeń 'Czarnego Łabędzia' (ekstremalne zyski ORAZ straty)",x ="Standaryzowany Zwrot Dzienny",y ="Gęstość" ) +theme_minimal(base_size =13) +theme(legend.position ="none",strip.text =element_text(face ="bold", size =12) )
Kluczowe Wnioski
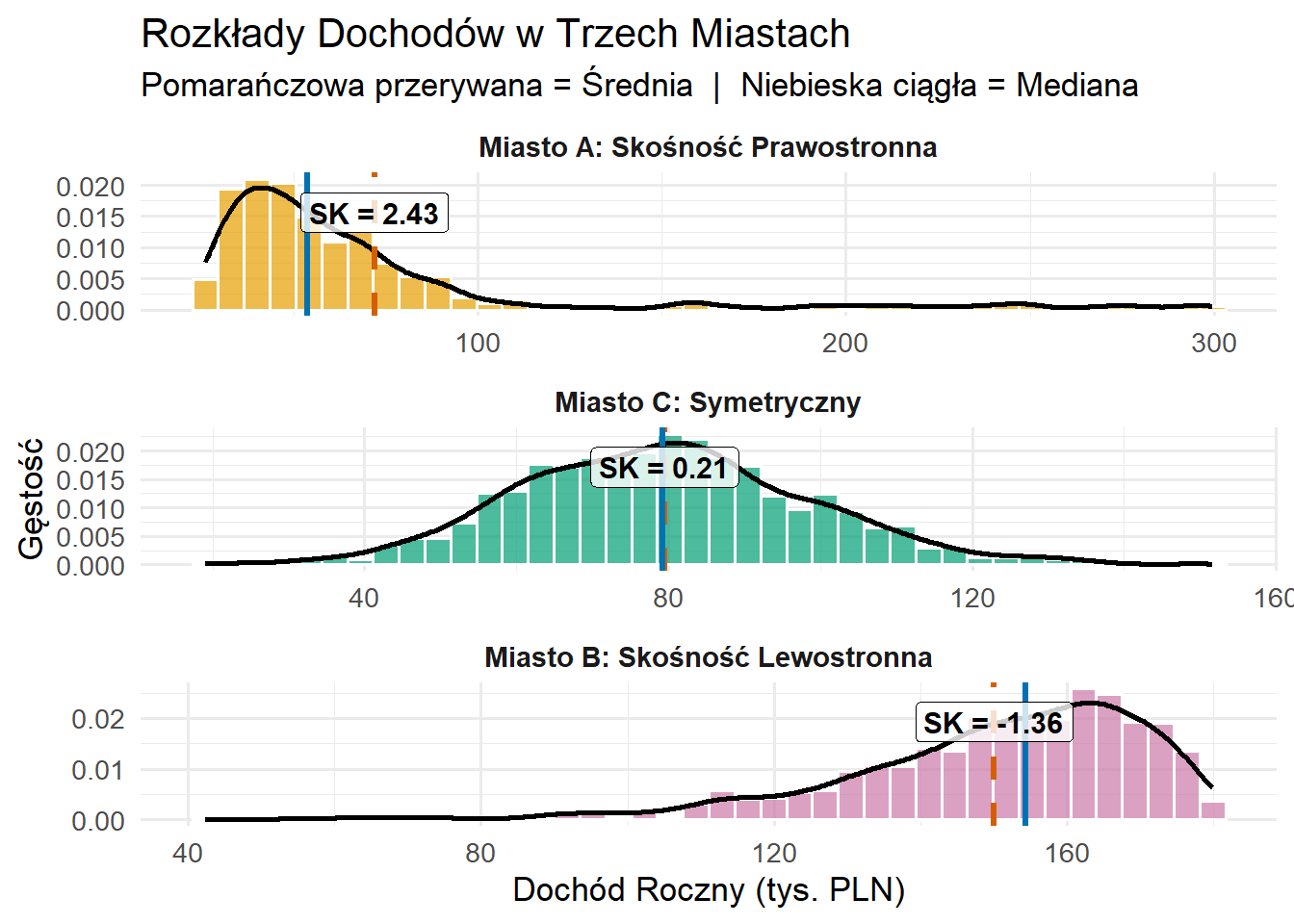
Skośność informuje o asymetrii:
Dodatnia: Długi prawy ogon → Średnia przesunięta powyżej mediany
Ujemna: Długi lewy ogon → Średnia przesunięta poniżej mediany
Kurtoza informuje o wartościach ekstremalnych:
Wysoka kurtoza (K > 5): Spodziewaj się częstych wartości odstających - zdarzenia typu “czarny łabędź”
Niska kurtoza (K < 2): Dane pozostają przewidywalne, w wąskich granicach
Normalna kurtoza (K ≈ 3): Typowe zachowanie krzywej dzwonowej
Wskazówki wizualne:
Skośność: Zwróć uwagę na długość ogonów - separację średniej od mediany
Kurtoza: Zwróć uwagę JEDNOCZEŚNIE na ostrość szczytu I grubość ogonów
Praktyczne znaczenie:
Wysoka kurtoza ≠ tylko “grube ogony” - to ostry szczyt RAZEM z ciężkimi ogonami
Oznacza to: “przeważnie skupione, ale uważaj na niespodzianki”
6.10 Ćwiczenie 1. Porównanie wynagrodzeń
Dane
Mamy dane o wynagrodzeniach (w tysiącach euro) z dwóch małych firm europejskich:
Index
Firma X
Firma Y
1
2
3
2
2
3
3
2
4
4
3
4
5
3
4
6
3
4
7
3
4
8
3
4
9
3
5
10
4
5
11
4
5
12
4
5
13
4
5
14
4
5
15
5
6
16
5
6
17
5
6
18
5
7
19
20
7
20
35
8
Miary tendencji centralnej
Średnia arytmetyczna
Średnia arytmetyczna to suma wszystkich wartości podzielona przez ich liczbę.
Wzór: \bar{x} = \frac{\sum_{i=1}^{n} x_i}{n}
Można też zapisać ten wzór w postaci:
\bar{x} = \frac{\sum_{i=1}^{k} x_i f_i}{n}
gdzie f_i to częstość bezwzględna (liczba wystąpień, waga bezwzględna) i-tej wartości, a k to liczba różnych wartości cechy (liczba wartości wyróżnionych).
Z użyciem częstości względnych:
\bar{x} = \sum_{i=1}^{k} x_i p_i
gdzie p_i to częstość względna (frakcja, waga znormalizowana) i-tej wartości, a k to liczba różnych wartości cechy (liczba wartości wyróżnionych).
Obliczenia ręczne dla Firmy X
Wartość (x_i)
Częstość (f_i)
x_i \cdot f_i
2
3
6
3
6
18
4
5
20
5
4
20
20
1
20
35
1
35
Suma
n = 20
Suma = 119
\bar{x} = \frac{119}{20} = 5,95
Obliczenia ręczne dla Firmy Y
Wartość (x_i)
Częstość (f_i)
x_i \cdot f_i
3
2
6
4
6
24
5
6
30
6
3
18
7
2
14
8
1
8
Suma
n = 20
Suma = 100
\bar{y} = \frac{100}{20} = 5
Weryfikacja w R
X <-c(2,2,2,3,3,3,3,3,3,4,4,4,4,4,5,5,5,5,20,35)Y <-c(3,3,4,4,4,4,4,4,5,5,5,5,5,5,6,6,6,7,7,8)mean(X)
[1] 5.95
mean(Y)
[1] 5
Mediana
Mediana to wartość środkowa w uporządkowanym zbiorze danych.
Poprawka Bessela jest stosowana przy obliczaniu wariancji z próby, aby uzyskać nieobciążony estymator wariancji populacji. W standardowym wzorze na wariancję z próby dzielimy przez (n-1) zamiast przez n.
Modyfikacje wzoru dla danych pogrupowanych (szereg częstości):
Q1 (25. percentyl): mediana pierwszych 10 liczb = 4
Q2 (50. percentyl, mediana): 5
Q3 (75. percentyl): mediana ostatnich 10 liczb = 6
Weryfikacja w R
quantile(X)
0% 25% 50% 75% 100%
2 3 4 5 35
quantile(Y)
0% 25% 50% 75% 100%
3 4 5 6 8
IQR
IQR_x = 5 - 3 = 2
IQR_y = 6 - 4 = 2
Wykres pudełkowy Tukeya
Wykres pudełkowy Tukeya wizualnie przedstawia rozkład danych na podstawie kwartyli. Użyjemy biblioteki ggplot2 do stworzenia wykresu.
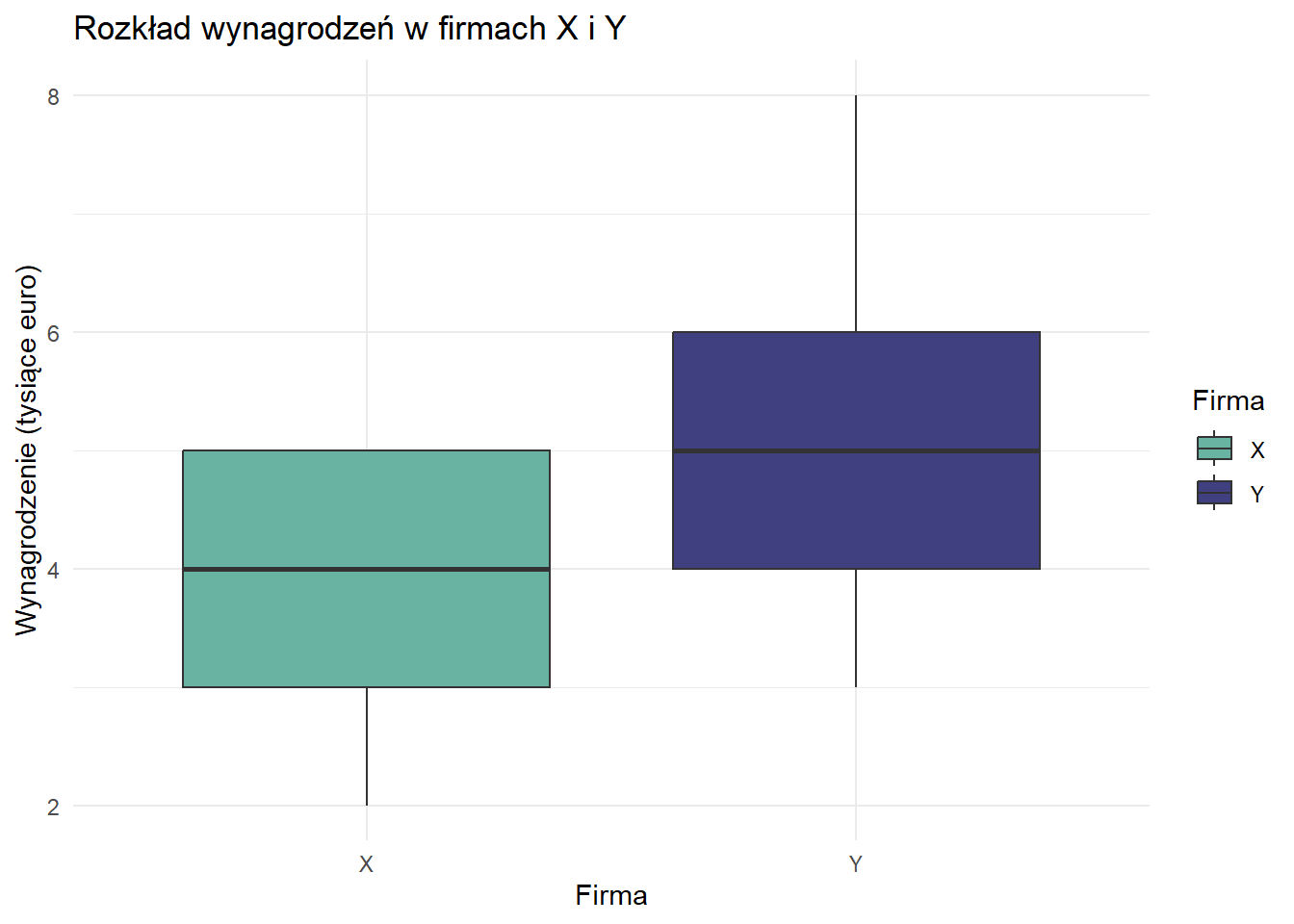
library(ggplot2)library(tidyr)# Przygotowanie danychdane <-data.frame(Firma =rep(c("X", "Y"), each =20),Wynagrodzenie =c(X, Y))# Tworzenie wykresu pudełkowegoggplot(dane, aes(x = Firma, y = Wynagrodzenie, fill = Firma)) +geom_boxplot() +labs(title ="Rozkład wynagrodzeń w firmach X i Y",x ="Firma",y ="Wynagrodzenie (tysiące euro)") +theme_minimal() +scale_fill_manual(values =c("X"="#69b3a2", "Y"="#404080"))
# Tworzenie wykresu pudełkowegoggplot(dane, aes(x = Firma, y = Wynagrodzenie, fill = Firma)) +geom_boxplot(outliers = F) +labs(title ="Rozkład wynagrodzeń w firmach X i Y",x ="Firma",y ="Wynagrodzenie (tysiące euro)") +theme_minimal() +scale_fill_manual(values =c("X"="#69b3a2", "Y"="#404080"))
Interpretacja wykresu pudełkowego
Pudełko reprezentuje rozstęp międzykwartylowy (IQR) od Q1 do Q3.
Linia wewnątrz pudełka to mediana (Q2).
Wąsy rozciągają się do najmniejszych i największych wartości w granicach 1,5 * IQR.
Punkty poza wąsami są uznawane za wartości odstające.
Porównanie wyników
Miara
Firma X
Firma Y
Średnia
5,95
5,00
Mediana
4
5
Dominanta
3
4 i 5
Wariancja
61,21
1,79
Odchylenie standard.
7,82
1,34
Q1
3
4
Q3
5
6
Kluczowe obserwacje:
Tendencja centralna: Firma X ma wyższą średnią, ale niższą medianę niż Firma Y, co wskazuje na prawostronnie skośny rozkład dla Firmy X.
Rozproszenie: Firma X wykazuje znacznie wyższą wariancję i odchylenie standardowe, sugerując większe dysproporcje w wynagrodzeniach.
Kształt rozkładu: Wynagrodzenia w Firmie Y są bardziej skupione, podczas gdy Firma X ma wartości ekstremalne (potencjalne wartości odstające), które znacząco wpływają na jej średnią i wariancję.
Kwartyle: Rozstęp międzykwartylowy (Q3 - Q1) Firmy Y jest nieznacznie większy, ale jej ogólny zakres jest znacznie mniejszy niż Firmy X.
6.11 Ćwiczenie 2. Porównanie Zmienności Wielkości Okręgów Wyborczych Między Krajami
Dane
Mamy dane o wielkości okręgów wyborczych z dwóch krajów:
x <-c(1, 3, 5, 7, 9, 11, 13, 15, 17, 19) # Kraj wysoka zmiennośćy <-c(8, 9, 9, 10, 10, 11, 11, 12, 12, 13) # Kraj niska zmiennośćkable(data.frame("Kraj X (Wysoka zm.)"= x,"Kraj Y (Niska zm.)"= y))
Kraj.X..Wysoka.zm..
Kraj.Y..Niska.zm..
1
8
3
9
5
9
7
10
9
10
11
11
13
11
15
12
17
12
19
13
Miary Tendencji Centralnej
Średnia Arytmetyczna
Wzór: \bar{x} = \frac{\sum_{i=1}^{n} x_i}{n}
Obliczenia dla Kraju X
Element
Wartość
1
1
2
3
3
5
4
7
5
9
6
11
7
13
8
15
9
17
10
19
Suma
100
\bar{x} = \frac{100}{10} = 10
mean_x <-mean(x)c("Ręcznie"=10, "R"= mean_x)
Ręcznie R
10 10
Obliczenia dla Kraju Y
Element
Wartość
1
8
2
9
3
9
4
10
5
10
6
11
7
11
8
12
9
12
10
13
Suma
105
\bar{y} = \frac{105}{10} = 10,5
mean_y <-mean(y)c("Ręcznie"=10.5, "R"= mean_y)
Ręcznie R
10.5 10.5
Mediana
Mediana to wartość środkowa w uporządkowanym zbiorze danych.
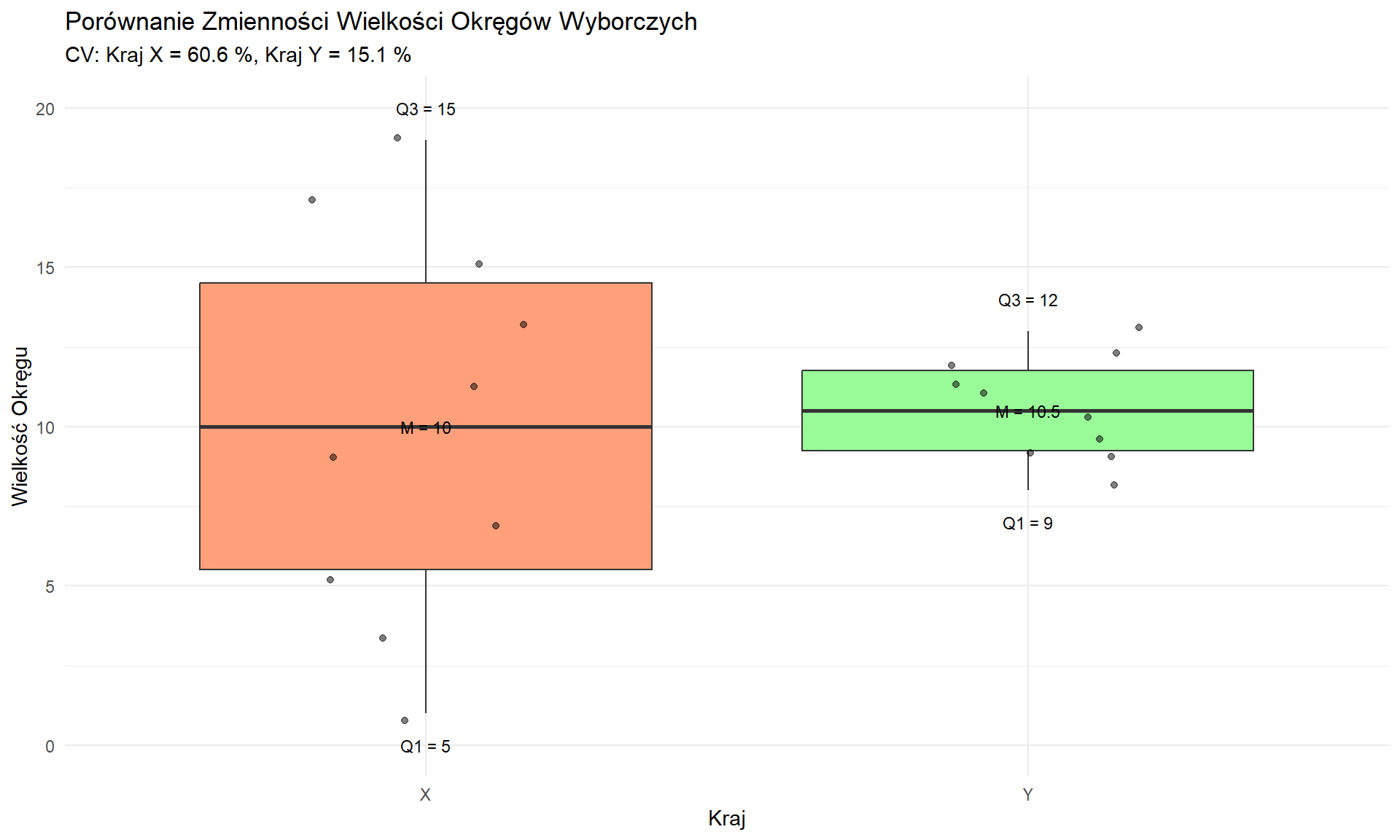
df_long <-data.frame(kraj =rep(c("X", "Y"), each =10),wielkosc =c(x, y))# Wykres podstawowyp <-ggplot(df_long, aes(x = kraj, y = wielkosc, fill = kraj)) +geom_boxplot(outlier.shape =NA) +# Wyłączamy domyślne punkty odstającegeom_jitter(width =0.2, alpha =0.5) +# Dodajemy punkty z przezroczystościąscale_fill_manual(values =c("X"="#FFA07A", "Y"="#98FB98")) +labs(title ="Porównanie Zmienności Wielkości Okręgów Wyborczych",subtitle =paste("CV: Kraj X =", round(cv_x, 1), "%, Kraj Y =", round(cv_y, 1), "%"),x ="Kraj",y ="Wielkość Okręgu" ) +theme_minimal() +theme(legend.position ="none")# Dodajemy adnotacje z kwartylamip +annotate("text", x =c(1, 1, 1, 2, 2, 2), y =c(max(x)+1, mean(x), min(x)-1, max(y)+1, mean(y), min(y)-1),label =c(paste("Q3 =", quantile(x, 0.75, type=1)),paste("M =", median(x)),paste("Q1 =", quantile(x, 0.25, type=1)),paste("Q3 =", quantile(y, 0.75, type=1)),paste("M =", median(y)),paste("Q1 =", quantile(y, 0.25, type=1)) ),size =3)
Uwagi Metodologiczne
Obliczenia kwartyli:
Zastosowana metoda wyłączająca medianę może dawać inne wyniki niż domyślne funkcje R
Różnice w metodach obliczeniowych nie wpływają na ogólne wnioski
Warto zawsze zaznaczyć stosowaną metodę w raportach
Wizualizacja:
Wykres pudełkowy skutecznie pokazuje różnice w rozkładach
Dodatkowe punkty pokazują rzeczywiste wartości
Adnotacje ułatwiają interpretację
Podsumowanie
Porównanie Miar Statystycznych
Miara
Kraj X
Kraj Y
Różnica względna
Średnia
10,0
10,5
Podobna
Mediana
10,0
10,5
Podobna
Dominanta
Brak
Wielokrotna (9,10,11,12)
-
Rozstęp
18
5
3,6× większy w X
Wariancja
36,67
2,5
14,7× większa w X
IQR
10
3
3,3× większy w X
CV
60,6%
15,0%
4,0× większy w X
Charakterystyka Rozkładów
Kraj X:
Rozkład równomierny
Brak dominującej wielkości okręgu (brak dominanty)
Szeroki zakres: od 1 do 19 mandatów
Wysoka zmienność (CV = 60,6%)
Równomierne rozłożenie wartości w zakresie
Kraj Y:
Rozkład skupiony
Wiele typowych wielkości (cztery dominanty)
Wąski zakres: od 8 do 13 mandatów
Niska zmienność (CV = 15,0%)
Wartości skoncentrowane wokół średniej
Interpretacja Wykresu Pudełkowego
Wizualizacja w formie wykresu pudełkowego pokazuje:
Elementy Struktury:
Pudełko: Pokazuje rozstęp międzykwartylowy (IQR)
Dolna krawędź: Pierwszy kwartyl (Q1)
Górna krawędź: Trzeci kwartyl (Q3)
Linia wewnętrzna: Mediana (Q2)
Wąsy: Rozciągają się do ±1,5 IQR - Punkty: Pojedyncze wielkości okręgów
Główne Wnioski Wizualne:
Rozmiar Pudełka:
Kraj X: Duże pudełko wskazuje na szeroki rozrzut środkowych 50%
Kraj Y: Małe pudełko pokazuje skupienie wartości środkowych
Długość Wąsów:
Kraj X: Długie wąsy wskazują na szeroki rozkład całkowity
Kraj Y: Krótkie wąsy pokazują ograniczony rozrzut
Rozkład Punktów:
Kraj X: Punkty szeroko rozproszone
Kraj Y: Punkty gęsto skupione
Kluczowe Obserwacje
Tendencja Centralna:
Podobne średnie wielkości okręgów
Różne wzorce rozkładu
Odmienne podejścia do standaryzacji
Miary Zmienności:
Wszystkie miary pokazują 3-15 razy większą zmienność w Kraju X
Spójny wzorzec w różnych miarach statystycznych
Systematyczna różnica w projekcie okręgów
Projekt Systemu:
Kraj X: Elastyczne, zróżnicowane podejście
Kraj Y: Ustandaryzowane, jednolite podejście
Różne filozoficzne podejścia do reprezentacji
Implikacje Reprezentatywności:
Kraj X: Zmienna proporcja wyborców do przedstawicieli
Kraj Y: Bardziej spójne poziomy reprezentacji
Różne podejścia do reprezentacji demokratycznej
Analiza ta pokazuje fundamentalne różnice w projektowaniu systemów wyborczych między dwoma krajami, gdzie Kraj X przyjmuje bardziej zróżnicowane podejście, a Kraj Y utrzymuje większą jednolitość w wielkości okręgów wyborczych.
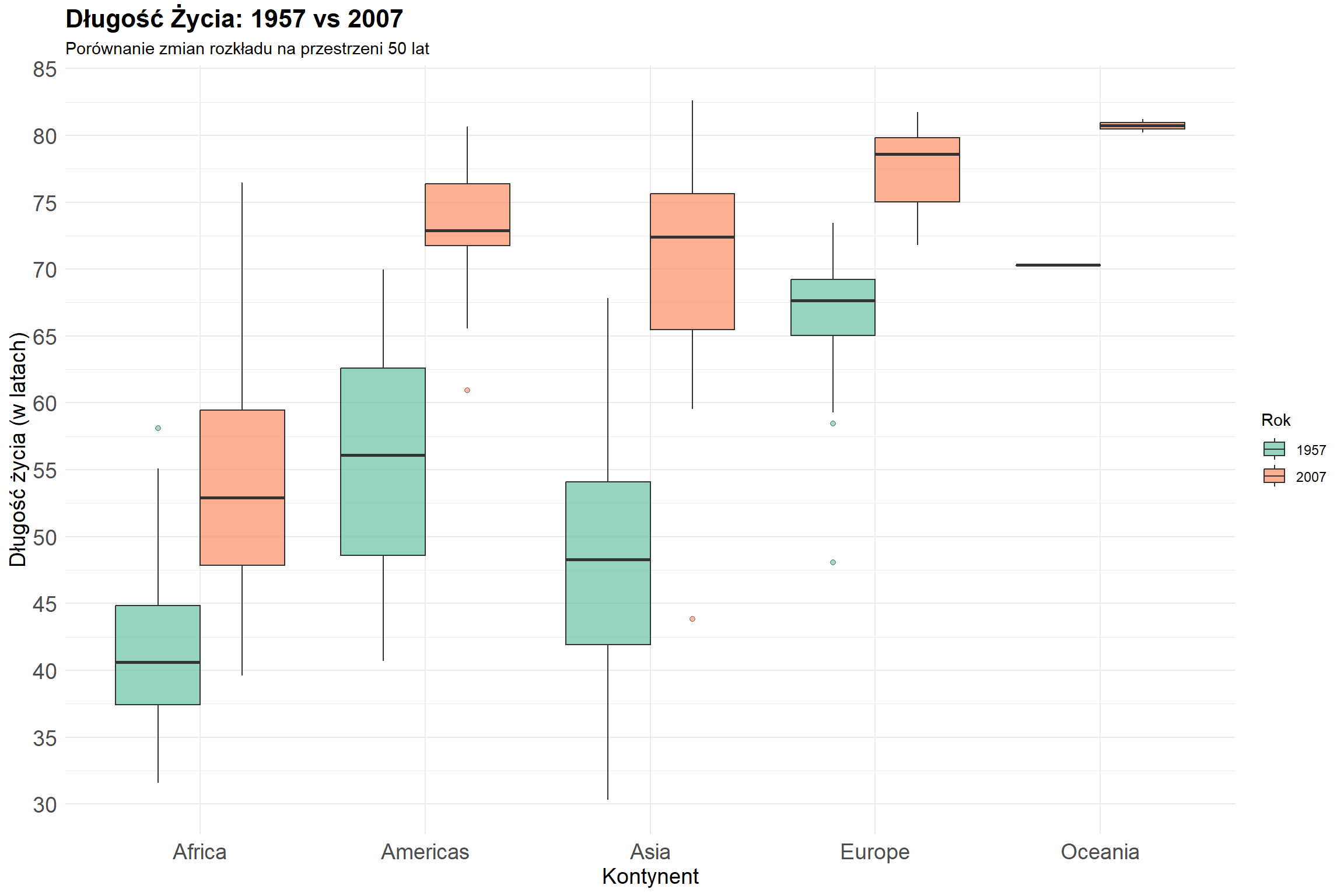
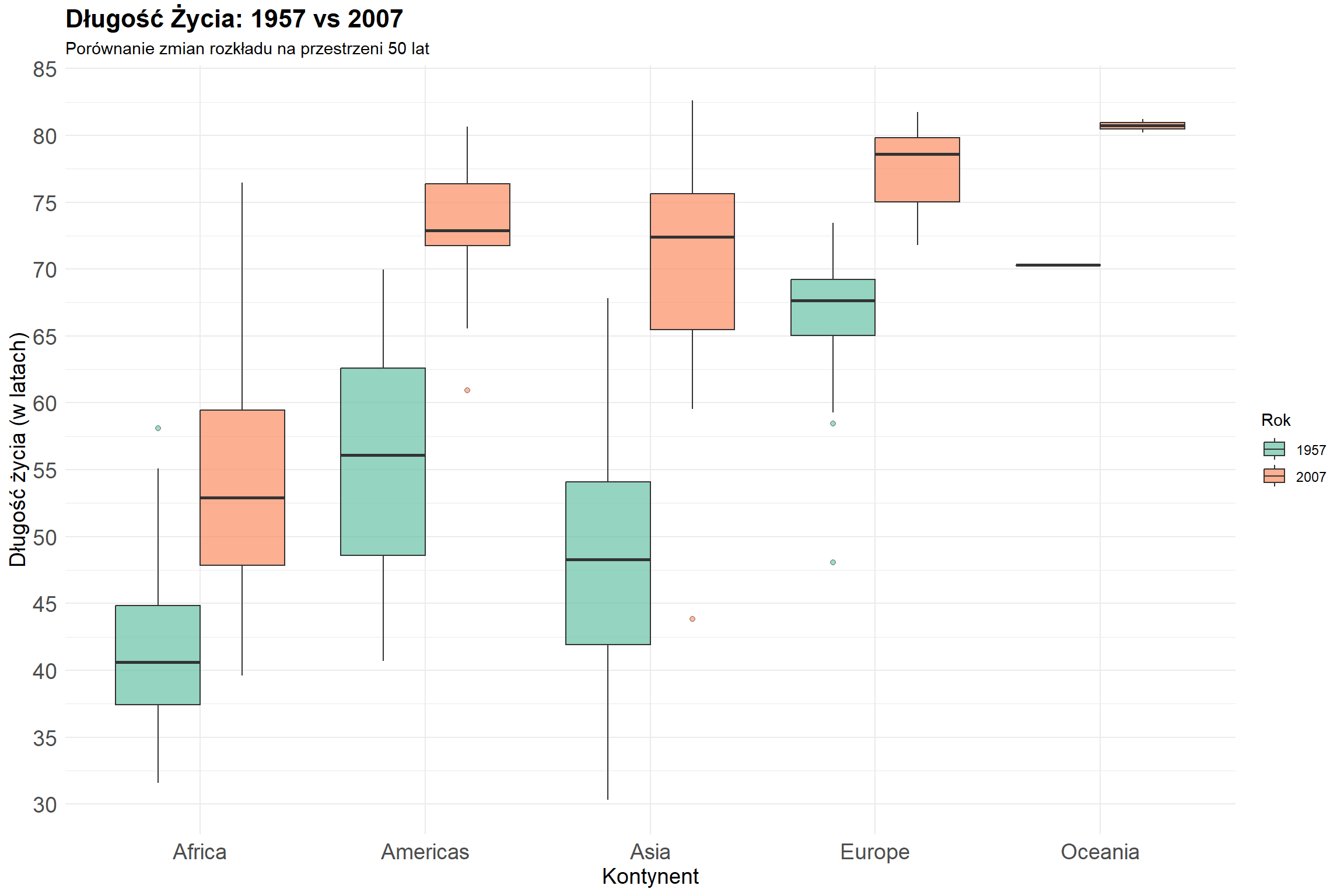
6.12 Cwiczenie 3. Wykresy Pudełkowe na Przykładzie Danych o Długości Życia
- Wykorzystuje wszystkie punkty danych - Podstawa wielu procedur statystycznych
- Wrażliwa na wartości odstające - Jednostki są podniesione do kwadratu (mniej intuicyjne)
Interwałowe, Ilorazowe, niektóre Dyskretne, Ciągłe
Odchylenie standardowe
- Wykorzystuje wszystkie punkty danych - Te same jednostki co oryginalne dane - Szeroko stosowane i zrozumiałe
- Wrażliwe na wartości odstające - Zakłada w przybliżeniu rozkład normalny dla interpretacji
Interwałowe, Ilorazowe, niektóre Dyskretne, Ciągłe
Współczynnik zmienności
- Pozwala na porównanie między zbiorami danych o różnych jednostkach lub średnich
- Może być mylący, gdy średnie są bliskie zeru - Bez znaczenia dla danych z wartościami ujemnymi
Ilorazowe, niektóre Interwałowe
Miary Korelacji/Asocjacji
Miara
Zalety
Wady
Zastosowanie do
r Pearsona
- Mierzy zależność liniową - Szeroko stosowany i zrozumiały
- Zakłada rozkład normalny - Wrażliwy na wartości odstające - Uchwytuje tylko zależności liniowe
Interwałowe, Ilorazowe, Ciągłe
Rho Spearmana
- Może być stosowany do danych porządkowych - Uchwytuje zależności monotoniczne - Mniej wrażliwy na wartości odstające
- Traci informacje przez konwersję na rangi - Może pominąć niektóre typy zależności
Porządkowe, Interwałowe, Ilorazowe
Tau Kendalla
- Może być stosowany do danych porządkowych - Bardziej odporny niż Spearman dla małych próbek - Ma ładną interpretację (prawdopodobieństwo zgodności)
- Traci informacje, biorąc pod uwagę tylko porządek - Bardziej intensywny obliczeniowo
Porządkowe, Interwałowe, Ilorazowe
Chi-kwadrat
- Może być stosowany do danych nominalnych - Testuje niezależność zmiennych kategorycznych
- Wymaga dużych rozmiarów próbek - Wrażliwy na rozmiar próbki - Nie mierzy siły asocjacji
Nominalne, Porządkowe
V Craméra
- Może być stosowany do danych nominalnych - Dostarcza miarę siły asocjacji - Znormalizowany do zakresu [0,1]
- Interpretacja może być subiektywna - Może przeszacować asocjację w małych próbkach
Nominalne, Porządkowe
Statistical Measures Applicability / Zastosowanie miar statystycznych
Measure (EN)
Miara (PL)
Nominal
Ordinal
Interval
Ratio
Central Tendency / Tendencja centralna:
Mode
Dominanta
✓
✓
✓
✓
Median
Mediana
-
✓
✓
✓
Arithmetic Mean
Średnia arytmetyczna
-
-
✓*
✓
Geometric Mean
Średnia geometryczna
-
-
-
✓
Harmonic Mean
Średnia harmoniczna
-
-
-
✓
Dispersion / Rozproszenie:
Range
Rozstęp
-
✓
✓
✓
Interquartile Range
Rozstęp międzykwartylowy
-
✓
✓
✓
Mean Absolute Deviation
Średnie odchylenie bezwzględne
-
-
✓
✓
Variance
Wariancja
-
-
✓*
✓
Standard Deviation
Odchylenie standardowe
-
-
✓*
✓
Coefficient of Variation
Współczynnik zmienności
-
-
-
✓
Association / Współzależność:
Chi-square
Chi-kwadrat
✓
✓
✓
✓
Spearman Correlation
Korelacja Spearmana
-
✓
✓
✓
Kendall’s Tau
Tau Kendalla
-
✓
✓
✓
Pearson Correlation
Korelacja Pearsona
-
-
✓*
✓
Covariance
Kowariancja
-
-
✓*
✓
* Theoretically problematic but commonly used in practice / Teoretycznie problematyczne, ale powszechnie stosowane w praktyce
Notes / Uwagi:
Measurement Scales / Skale pomiarowe:
Nominal: Categories without order / Kategorie bez uporządkowania
Ordinal: Ordered categories / Kategorie uporządkowane
Interval: Equal intervals, arbitrary zero / Równe interwały, umowne zero
Ratio: Equal intervals, absolute zero / Równe interwały, absolutne zero
Practical Considerations / Aspekty praktyczne:
Some measures marked with ✓* are commonly used for interval data despite theoretical issues / Niektóre miary oznaczone ✓* są powszechnie stosowane dla danych przedziałowych pomimo problemów teoretycznych
Choice of measure should consider both theoretical appropriateness and practical utility / Wybór miary powinien uwzględniać zarówno poprawność teoretyczną jak i użyteczność praktyczną
More restrictive scales (ratio) allow all measures from less restrictive scales / Bardziej restrykcyjne skale (ilorazowe) pozwalają na wszystkie miary z mniej restrykcyjnych skal