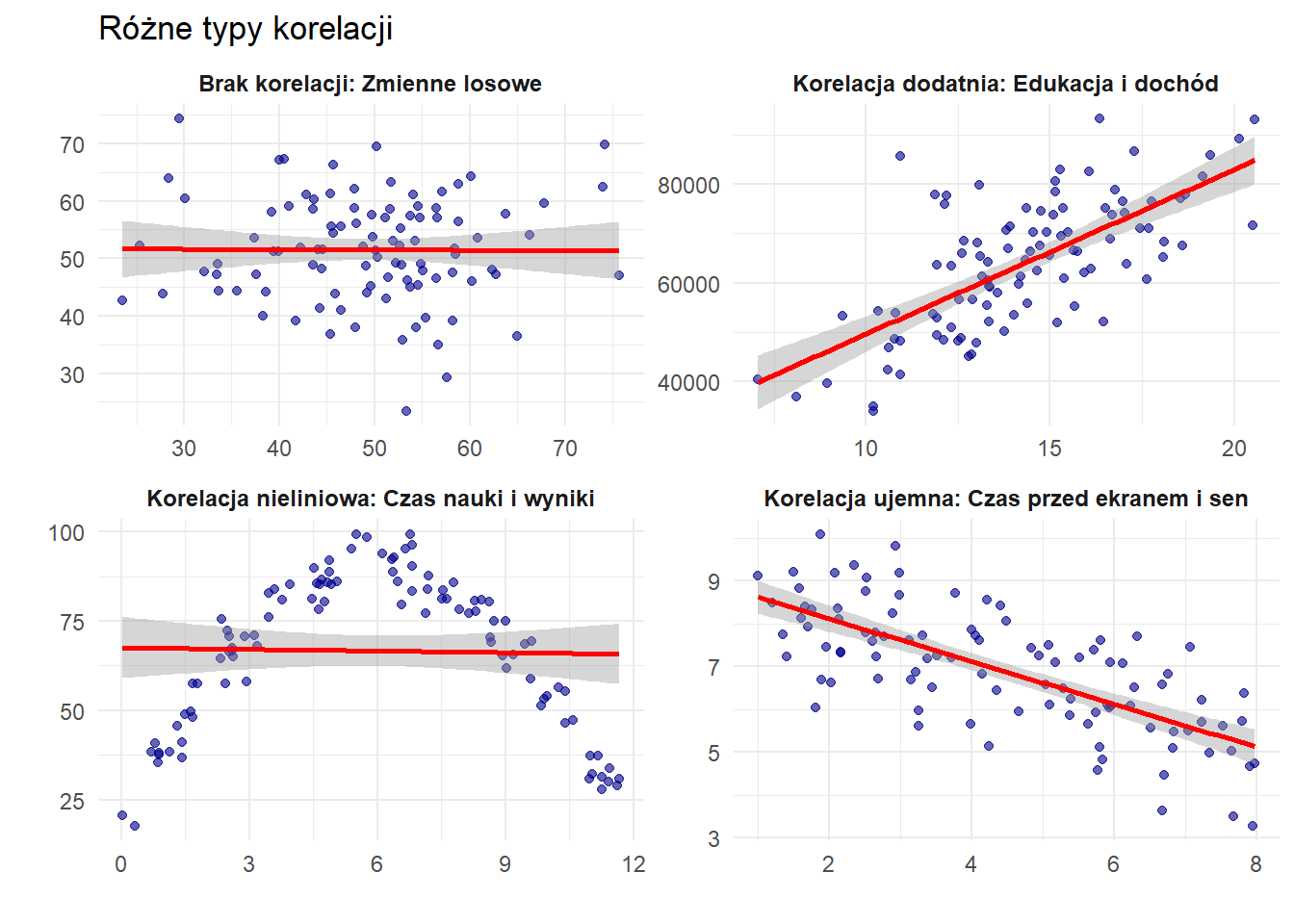
Różnica między korelacją (correlation) a przyczynowością/kausalnością (causation) to jedno z podstawowych wyzwań w analizie statystycznej. Korelacja mierzy statystyczny związek między zmiennymi, natomiast przyczynowość oznacza bezpośredni wpływ jednej zmiennej na drugą.
Zależności statystyczne stanowią fundament podejmowania decyzji opartych na danych w wielu dyscyplinach — od ekonomii i zdrowia publicznego po psychologię i nauki o środowisku. Zrozumienie, kiedy związek wskazuje jedynie na asocjację (association), a kiedy na prawdziwą kausalność (genuine causality), jest kluczowe dla poprawnych wniosków i skutecznych rekomendacji politycznych.
10.2 Kowariancja (Covariance)
Kowariancja (covariance) mierzy, w jaki sposób dwie zmienne współzmieniają się, wskazując zarówno kierunek, jak i siłę ich liniowego związku.
Interpretacja: Dodatnia kowariancja (37.5) wskazuje, że wraz ze wzrostem liczby godzin nauki rosną także wyniki testu — zmienne mają tendencję do wspólnego wzrostu.
Zadanie ćwiczeniowe z rozwiązaniem (Practice Problem with Solution)
cat("\nStandard deviation of X:", sd(study_hours))
Standard deviation of X: 3.162278
cat("\nStandard deviation of Y:", sd(test_scores))
Standard deviation of Y: 11.93734
# Przedział ufności i p-valuecor_test <-cor.test(study_hours, test_scores, method ="pearson")print(cor_test)
Pearson's product-moment correlation
data: study_hours and test_scores
t = 15, df = 3, p-value = 0.0006431
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.8994446 0.9995859
sample estimates:
cor
0.9933993
Interpretacja:r \approx 0.994 wskazuje na niemal doskonały dodatni liniowy związek między godzinami nauki a wynikiem testu. Wartość p < 0.05 sugeruje statystyczną istotność tej zależności.
10.5 Korelacja rang Spearmana (Spearman Rank Correlation)
Korelacja Spearmana mierzy monotoniczne zależności, używając rang zamiast surowych wartości.
r = 0.85 między godzinami treningu a wynikiem sprawdzianu sprawności
Odpowiedź: Silny dodatni związek. Wraz ze wzrostem liczby godzin treningu wyniki istotnie rosną.
r = -0.72 między temperaturą na zewnątrz a kosztami ogrzewania
Odpowiedź: Silny ujemny związek. Wraz ze wzrostem temperatury koszty ogrzewania wyraźnie maleją.
r = 0.12 między rozmiarem buta a inteligencją
Odpowiedź: Bardzo słaby/brak istotnego związku. Zmienne są praktycznie niezależne.
10.8 Najważniejsze rzeczy do zapamiętania (Important Points to Remember)
Korelacja mierzy siłę związku: Wartości od -1 do +1.
Korelacja ≠ przyczynowość (Correlation ≠ Causation): Wysoka korelacja nie dowodzi wpływu jednej zmiennej na drugą.
Dobierz właściwą metodę:
Pearson: Związki liniowe dla danych ciągłych.
Spearman: Związki monotoniczne lub dane rangowe.
Sprawdź założenia:
Pearson: liniowość i (w praktyce) rozkład zbliżony do normalnego.
Spearman: wymagana jedynie monotoniczność.
Uwaga na obserwacje odstające (outliers): Mogą silnie wpływać na korelację Pearsona.
Zawsze wizualizuj dane: Wykresy pomagają ocenić kształt zależności.
10.9 Podsumowanie: drzewko decyzyjne do analizy korelacji (Summary: Decision Tree for Correlation Analysis)
WYBÓR WŁAŚCIWEJ MIARY KORELACJI:
Czy dane są liczbowe (numeryczne)?
├─ TAK → Czy związek jest liniowy?
│ ├─ TAK → Użyj korelacji PEARSONA
│ └─ NIE → Czy związek jest monotoniczny?
│ ├─ TAK → Użyj korelacji SPEARMANA
│ └─ NIE → Rozważ metody nieliniowe
└─ NIE → Czy dane są porządkowe (rangi)?
├─ TAK → Użyj korelacji SPEARMANA
└─ NIE → Użyj TABEL KRZYŻOWYCH dla danych kategorycznych
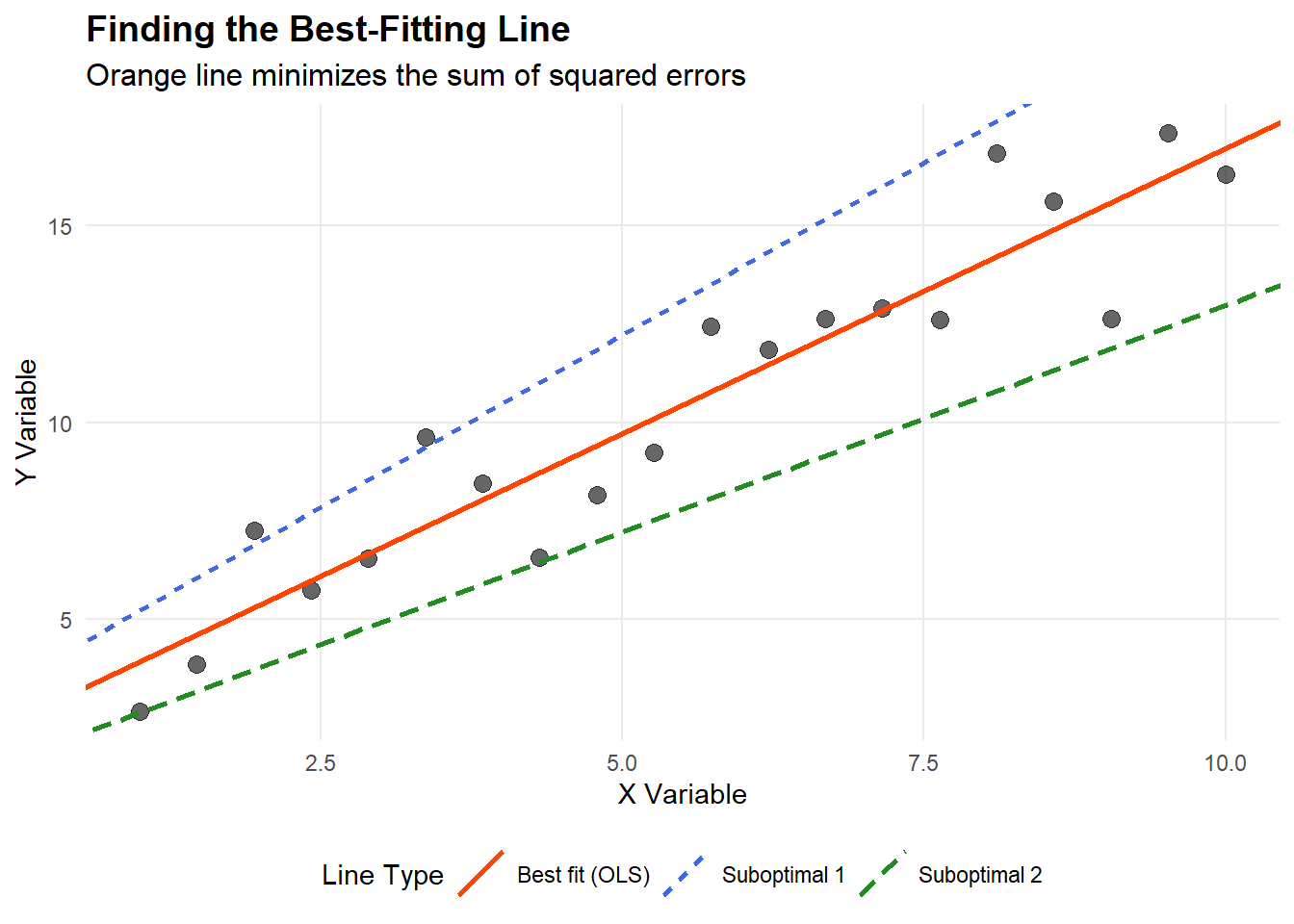
10.10 Analiza regresji OLS (Ordinary Least Squares): przewodnik na start (A Quick-start Guide)
Analiza regresji OLS: przewodnik na start
Wprowadzenie: czym jest analiza regresji?
Analiza regresji (regression analysis) pomaga zrozumieć i mierzyć zależności między obserwowalnymi wielkościami. To zestaw narzędzi matematycznych do identyfikowania wzorców w danych, które umożliwiają prognozowanie (prediction).
Rozważ pytania badawcze:
Jak czas nauki wpływa na wynik testu?
Jak doświadczenie wpływa na wynagrodzenie?
Jak wydatki na reklamę oddziałują na sprzedaż?
Regresja dostarcza systematycznych metod, by na te pytania odpowiadać na podstawie realnych danych.
Punkt wyjścia: prosty przykład
Zacznijmy od konkretu. Zebrano dane o 20 studentach z Twojej klasy:
Student
Study Hours
Exam Score
Alex
2
68
Beth
4
74
Carlos
6
85
Diana
8
91
…
…
…
Po narysowaniu wykresu punktowego (scatter plot) chcesz znaleźć prostą, która najlepiej opisuje związek między godzinami nauki a wynikiem.
Ale co znaczy „najlepiej”? Właśnie to odkryjemy.
Dlaczego prawdziwe dane nie układają się w idealną linię
Zanim przejdziemy do rachunków, zrozummy, dlaczego punkty zwykle nie leżą na jednej prostej.
Modele deterministyczne vs. stochastyczne
Modele deterministyczne (deterministic models) opisują związki bez niepewności. Przykład z fizyki:
\text{Distance} = \text{Speed} \times \text{Time}
Jedziesz dokładnie 60 mph przez 2 godziny → zawsze 120 mil. Zero odchyleń.
Modele stochastyczne (stochastic models) uznają, że w danych naturalnie występuje losowość. Ogólna postać to:
Y = f(X) + \epsilon
Gdzie:
Y — wielkość, którą prognozujemy (np. wynik testu),
f(X) — wzorzec systematyczny (jak godziny nauki typowo wpływają na wyniki),
\epsilon — „reszta”/szum: wszystko, czego nie mierzymy.
W naszym przykładzie dwoje studentów może uczyć się po 5 godzin, a jednak dostać różne oceny, bo:
jedno lepiej spało,
jedno ma talent do testów,
jedno miało hałas na sali,
pytania trafiły bardziej/mniej pod ich przygotowanie.
Ta losowość jest naturalna — tym zajmuje się \epsilon.
Prosty model regresji liniowej
Zależność między godzinami nauki a wynikiem zapisujemy jako:
Y_i = \beta_0 + \beta_1 X_i + \epsilon_i
Rozszyfrujmy:
Y_i — wynik testu studenta i,
X_i — godziny nauki studenta i,
\beta_0 — wyraz wolny (intercept, „poziom bazowy” przy 0 godzin),
\beta_1 — nachylenie (slope, przyrost punktów na godzinę),
\epsilon_i — „wszystko inne” wpływające na wynik i.
Ważne: Prawdziwych wartości \beta_0, \beta_1nie znamy. Szacujemy je z danych i oznaczamy „z daszkiem”: \hat{\beta}_0, \hat{\beta}_1.
Reszty: jak bardzo mylimy się w przewidywaniach?
Po dopasowaniu prostej możemy przewidzieć wyniki. Dla każdej obserwacji:
Wartość rzeczywista (y_i): faktyczny wynik,
Wartość przewidziana (\hat{y}_i): co „mówi” nasza prosta,
Nachylenie / Slope (\beta_1) PL: Przy wzroście X o 1 jednostkę (ceteris paribus), przeciętna wartość Y zmienia się o \beta_1 jednostek. ENG: When X increases by 1 unit (ceteris paribus), the expected value of Y changes by \beta_1 units.
gdzie s_X i s_Y to odchylenia standardowe X i Y. PL: Przy wzroście X o 1 odchylenie standardowe (SD), przeciętna wartość Y zmienia się o \beta_{1}^{(\mathrm{std})}odchyleń standardowychY. ENG: For a 1 standard deviation (SD) increase in X, the expected value of Y changes by \beta_{1}^{(\mathrm{std})}SDs ofY. Uwaga/Note: W regresji prostej \beta_{1}^{(\mathrm{std})} = r (Pearson). / In simple regression, \beta_{1}^{(\mathrm{std})} = r (Pearson).
PL: Model wyjaśnia 100\times R^2% zmienności Y względem modelu tylko z wyrazem wolnym (in-sample). ENG: The model explains 100\times R^2% of the variance in Y relative to the intercept-only model (in-sample). W wielu zmiennych rozważ: \text{adjusted } R^2. / With multiple predictors consider: adjusted R^2.
Wartość p / P-valueFormalnie/Formally:
p \;=\; \Pr\!\big(\,|T|\ge |t_{\mathrm{obs}}| \mid H_0\,\big),
gdzie T ma rozkład t przy H_0. PL: Zakładając prawdziwość H_0 i spełnione założenia modelu, prawdopodobieństwo uzyskania co najmniej tak ekstremalnej statystyki jak obserwowana wynosi p. ENG: Assuming H_0 and the model assumptions hold, p is the probability of observing a test statistic at least as extreme as the one obtained.
Przedział ufności / Confidence interval (np. dla\beta_1) Konstrukcja/Construction:
PL (ściśle): W długiej serii powtórzeń 95% tak skonstruowanych przedziałów zawiera prawdziwą wartość \beta_1; dla naszych danych oszacowanie mieści się w [\text{lower},\ \text{upper}]. ENG (strict): Over many repetitions, 95% of such intervals would contain the true \beta_1; for our data, the estimate lies within [\text{lower},\ \text{upper}]. PL (skrót dydaktyczny): „Jesteśmy 95% pewni, że \beta_1 leży w [\text{lower},\ \text{upper}].” ENG (teaching shorthand): “We are 95% confident that \beta_1 lies in [\text{lower},\ \text{upper}].”
Najczęstsze nieporozumienia / Common pitfalls
PL:pnie jest prawdopodobieństwem, że H_0 jest prawdziwa. ENG:p is not the probability that H_0 is true.
PL: 95% CI nie zawiera 95% obserwacji (od tego jest przedział predykcji). ENG: A 95% CI does not contain 95% of observations (that’s a prediction interval).
PL/ENG: Wysokie R^2 ≠ przyczynowość / High R^2 ≠ causality. Zawsze sprawdzaj/Always check diagnozy reszt, skalę efektu, i dopasowanie poza próbą.
Pamiętaj:
Asocjacja ≠ przyczynowość,
Istotność statystyczna ≠ istotność praktyczna,
„Każdy model jest błędny, niektóre są użyteczne”,
Zawsze wizualizuj dane i reszty,
Decyzje opieraj na wielkości efektu i niepewności.
OLS dostarcza uporządkowany, matematyczny sposób znajdowania wzorców w danych. Nie daje doskonałych prognoz, ale zapewnia najlepszą liniową aproksymację wraz z uczciwą oceną jej jakości i niepewności.
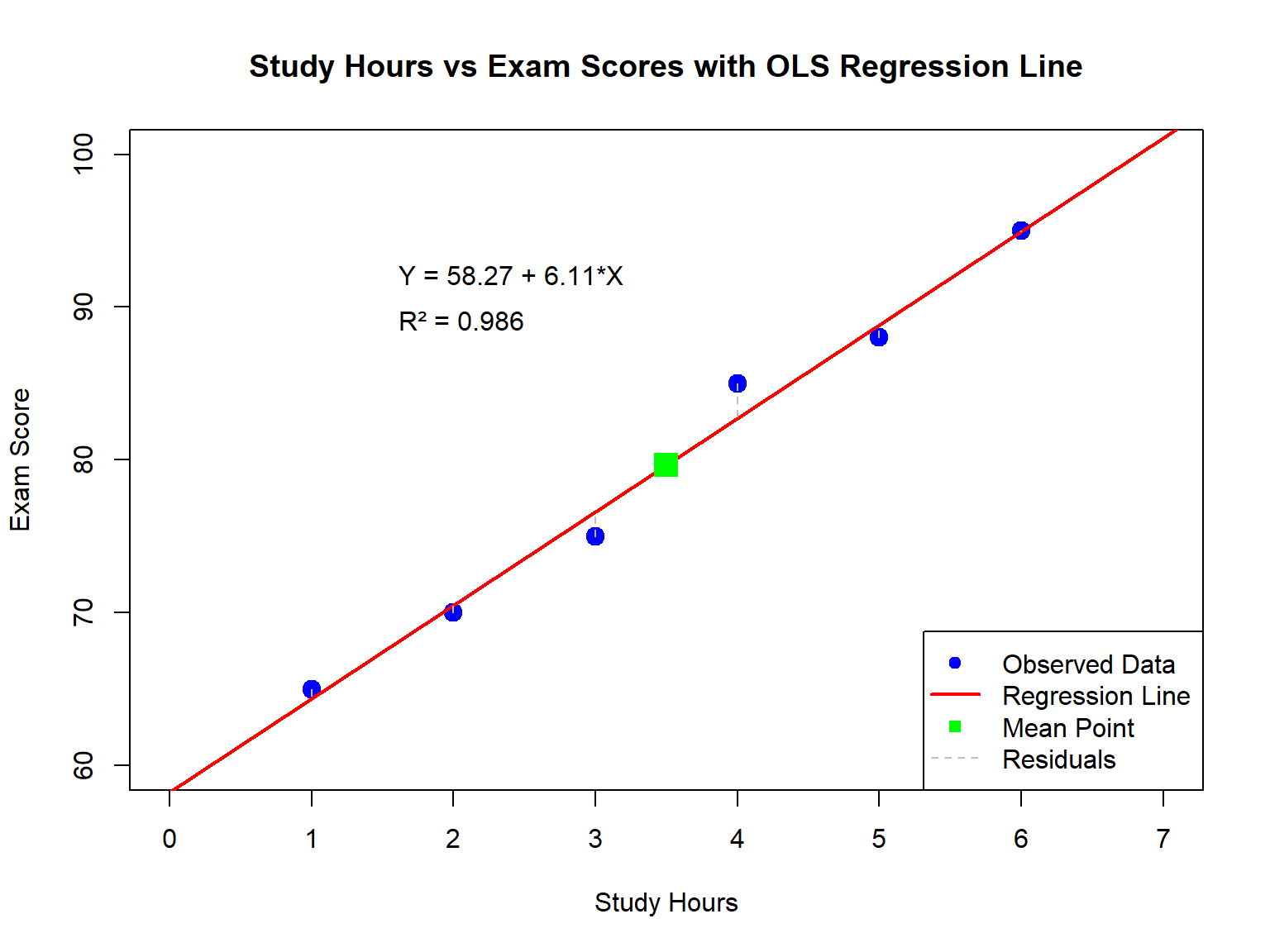
10.11 Ręczne obliczenia OLS krok po kroku
Badaczka chce zbadać zależność między godzinami nauki a wynikiem testu (6 studentów):
Student
Study Hours (X)
Exam Score (Y)
A
1
65
B
2
70
C
3
75
D
4
85
E
5
88
F
6
95
Celem jest wyznaczyć \hat{Y} = \hat{\beta}_0 + \hat{\beta}_1 X metodą OLS.
cat("R-squared:", round(R_squared_method1, 4), sprintf("(%.1f%% of variance explained)\n", R_squared_method1 *100))
R-squared: 0.9863 (98.6% of variance explained)
cat("Standardized Effect Size:", round(beta_std, 2), "(Very Large Effect)\n")
Standardized Effect Size: 0.99 (Very Large Effect)
cat("\nInterpretation:\n")
Interpretation:
cat("- Each additional hour of study increases exam score by", round(beta_1_manual, 2), "points\n")
- Each additional hour of study increases exam score by 6.11 points
cat("- Study hours explain", sprintf("%.1f%%", R_squared_method1 *100), "of the variation in exam scores\n")
- Study hours explain 98.6% of the variation in exam scores
cat("- The relationship is extremely strong (correlation =", round(correlation, 3), ")\n")
- The relationship is extremely strong (correlation = 0.993 )
10.13 Jak uruchomić kod
Skopiuj cały blok kodu,
Wklej do RStudio,
Uruchom chunk po chunk lub cały dokument,
Porównaj wyniki z obliczeniami ręcznymi.
Co zobaczysz:
Nachylenie: 6.12,
Wyraz wolny: 58.25,
R^2: ≈ 0.988,
Efekt standaryzowany: ≈ 0.99,
Wykres z punktami, linią regresji i resztami.
To potwierdza poprawność obliczeń manualnych.
10.14 Appendix A: Obliczanie Kowariancji, Korelacji Pearsona i Spearmana, oraz modelowanie OLS - przykład wprowadzający
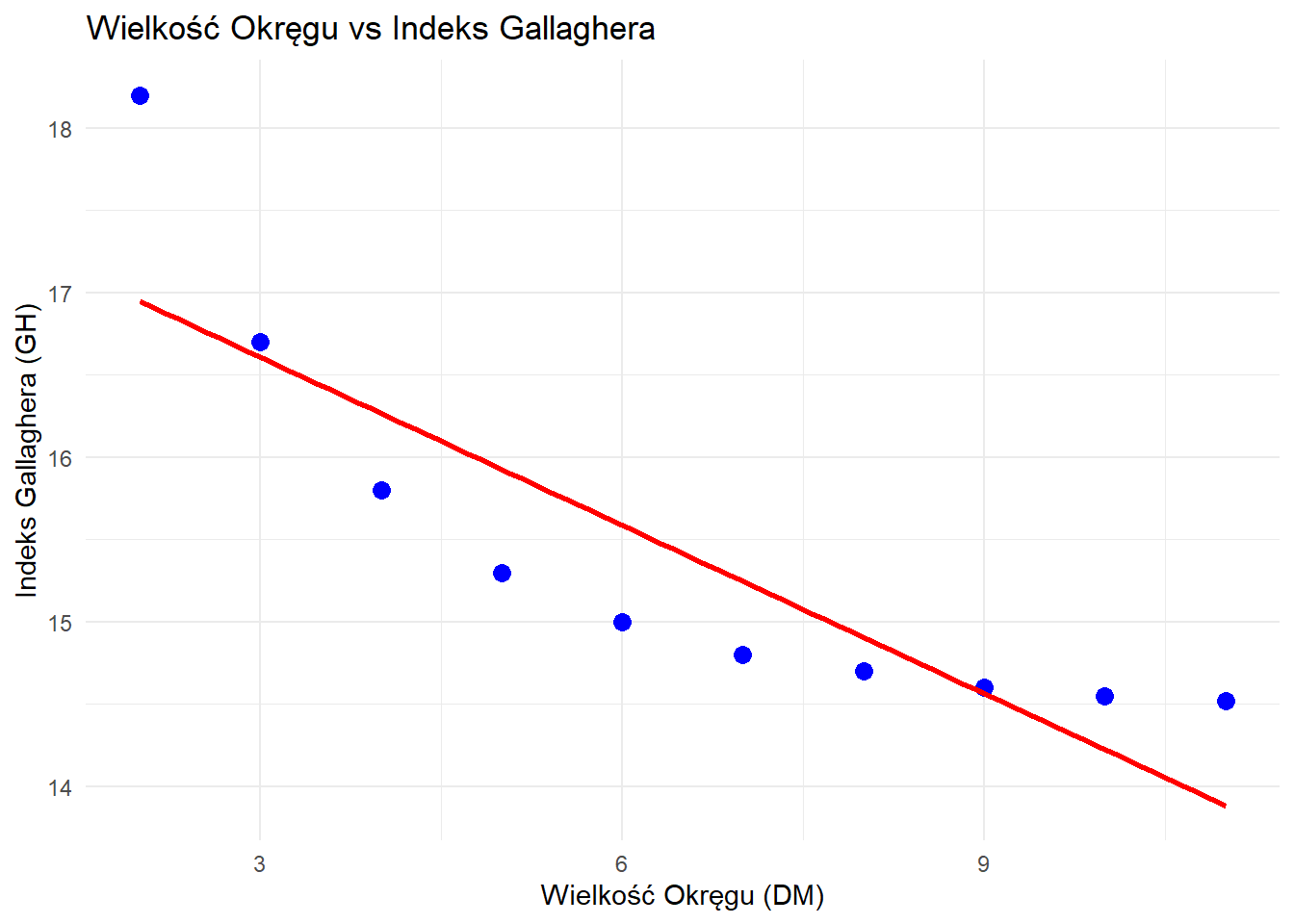
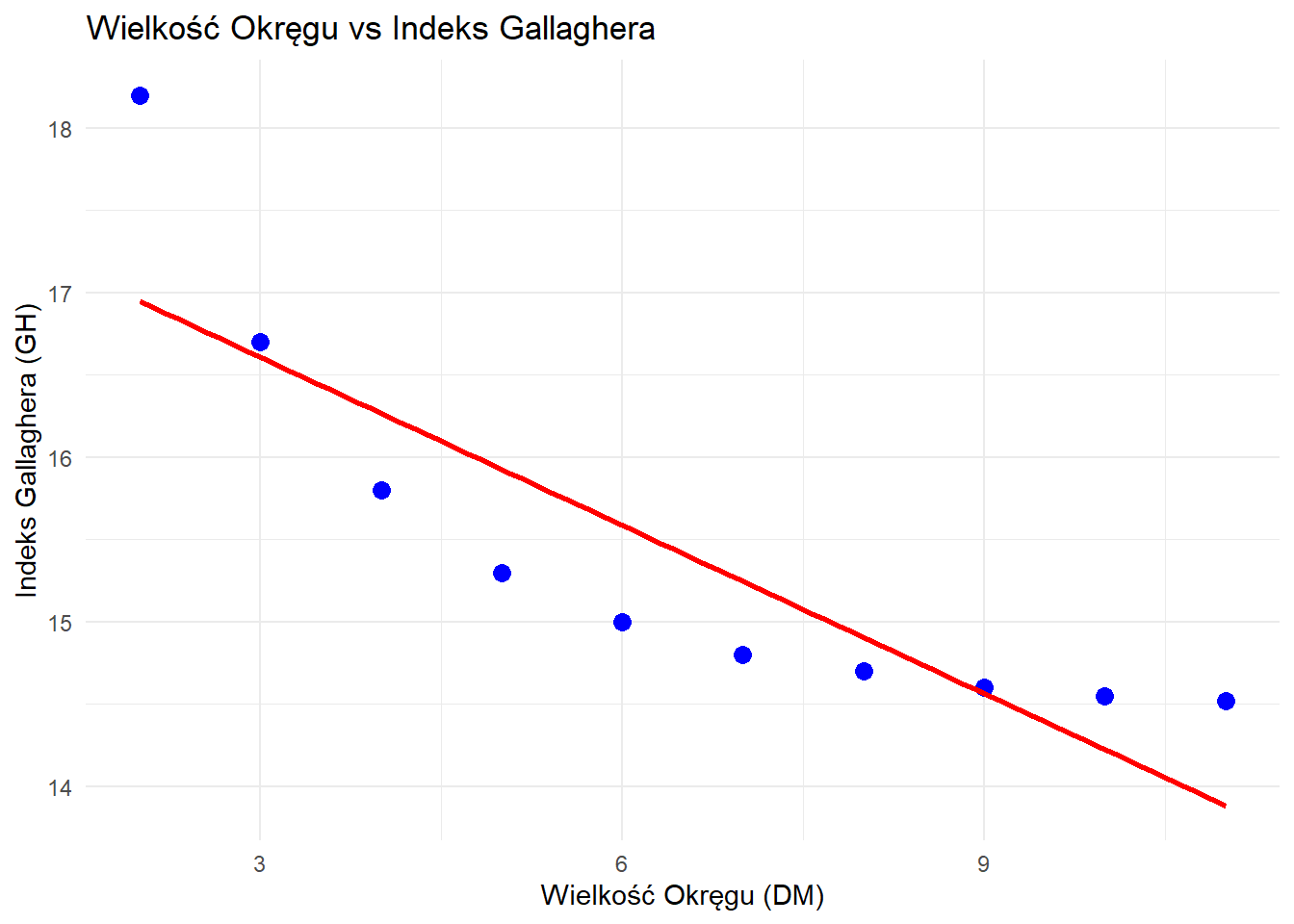
Studentka politologii bada związek między wielkością okręgu wyborczego (DM) a wskaźnikiem dysproporcjonalności Gallaghera (GH) w wyborach parlamentarnych w 10 losowo wybranych demokracjach.
Dane dotyczące wielkości okręgu wyborczego (\text{DM}) i indeksu Gallaghera:
\text{DM} (X)
Gallagher (Y)
2
18,2
3
16,7
4
15,8
5
15,3
6
15,0
7
14,8
8
14,7
9
14,6
10
14,55
11
14,52
Krok 1: Obliczanie Podstawowych Statystyk
Obliczanie średnich:
Dla \text{DM} (X): \bar{X} = \frac{\sum_{i=1}^n X_i}{n}
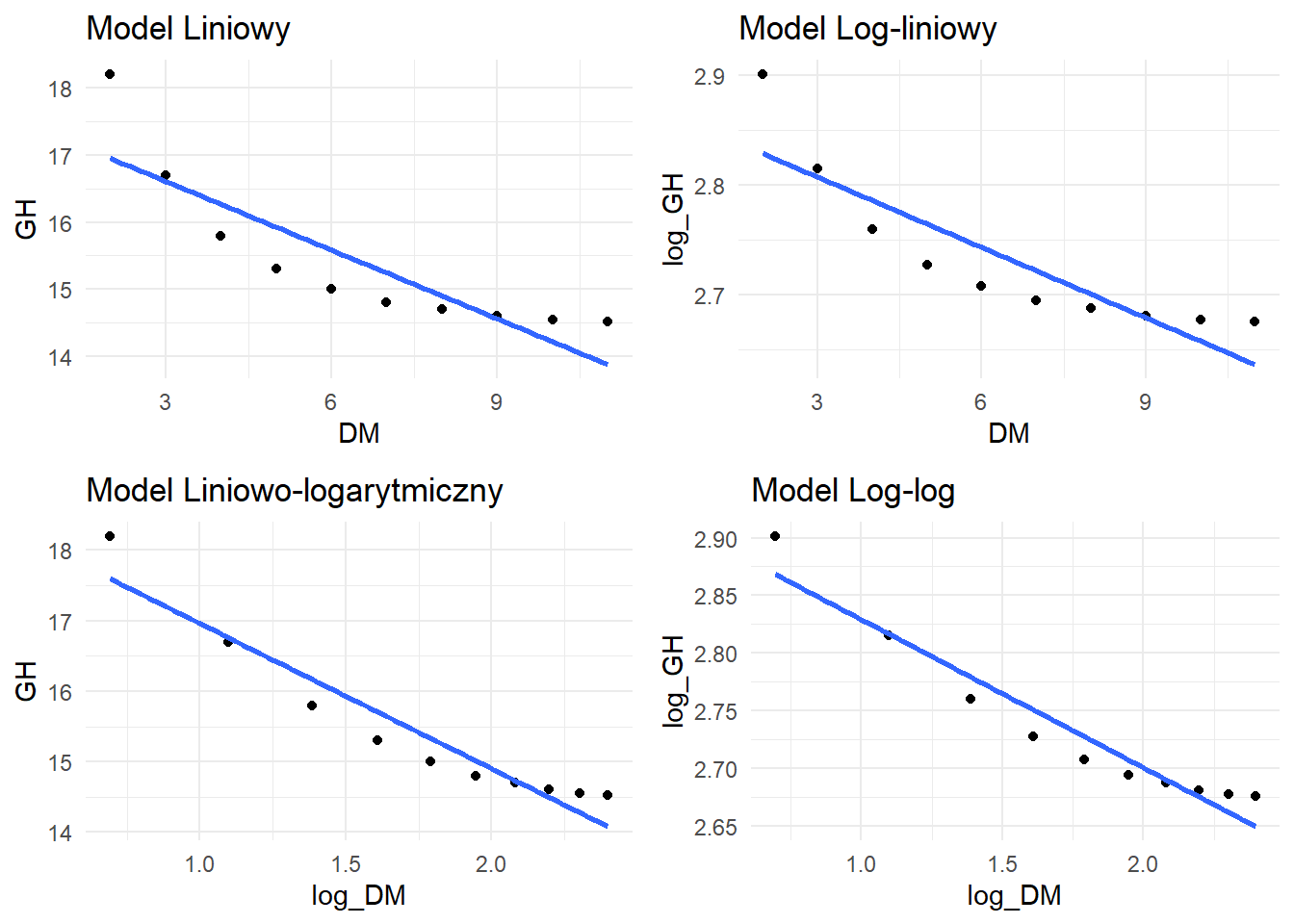
# Tworzenie wykresów dla każdego modelup1 <-ggplot(data, aes(x = DM, y = GH)) +geom_point() +geom_smooth(method ="lm", se =FALSE) +labs(title ="Model Liniowy") +theme_minimal()p2 <-ggplot(data, aes(x = DM, y = log_GH)) +geom_point() +geom_smooth(method ="lm", se =FALSE) +labs(title ="Model Log-liniowy") +theme_minimal()p3 <-ggplot(data, aes(x = log_DM, y = GH)) +geom_point() +geom_smooth(method ="lm", se =FALSE) +labs(title ="Model Liniowo-logarytmiczny") +theme_minimal()p4 <-ggplot(data, aes(x = log_DM, y = log_GH)) +geom_point() +geom_smooth(method ="lm", se =FALSE) +labs(title ="Model Log-log") +theme_minimal()# Układanie wykresów w siatkęlibrary(gridExtra)grid.arrange(p1, p2, p3, p4, ncol =2)
`geom_smooth()` using formula = 'y ~ x'
`geom_smooth()` using formula = 'y ~ x'
`geom_smooth()` using formula = 'y ~ x'
`geom_smooth()` using formula = 'y ~ x'
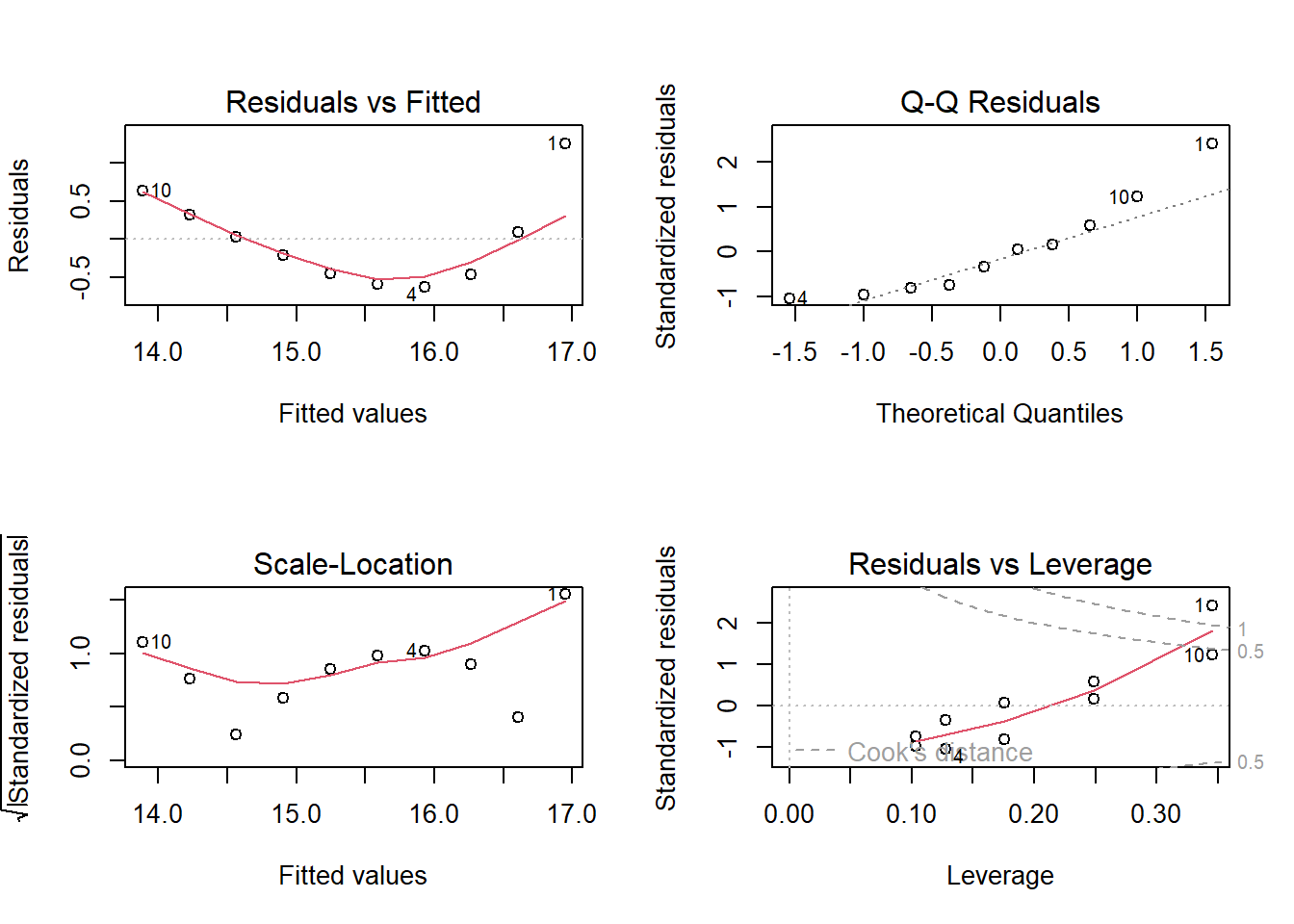
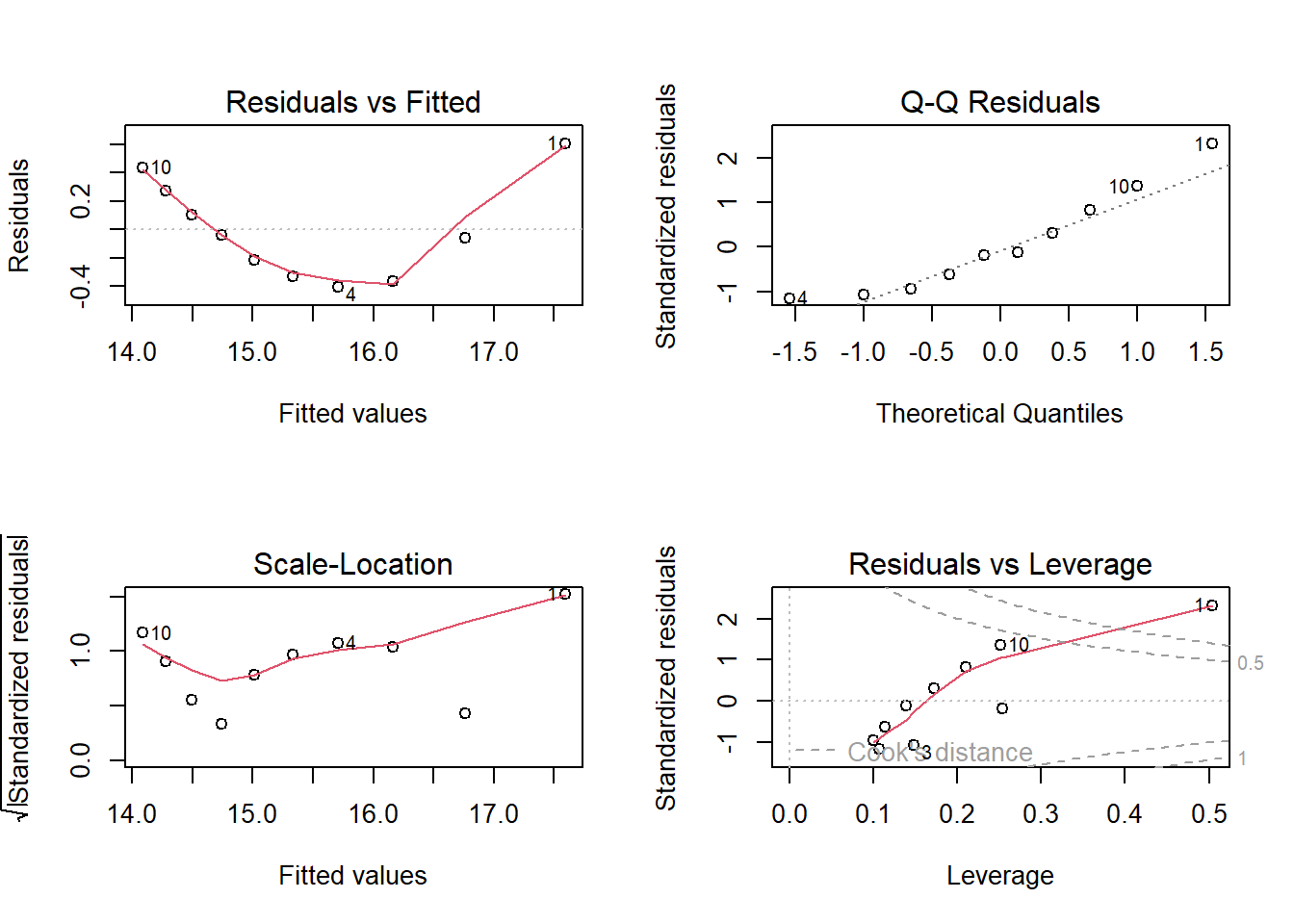
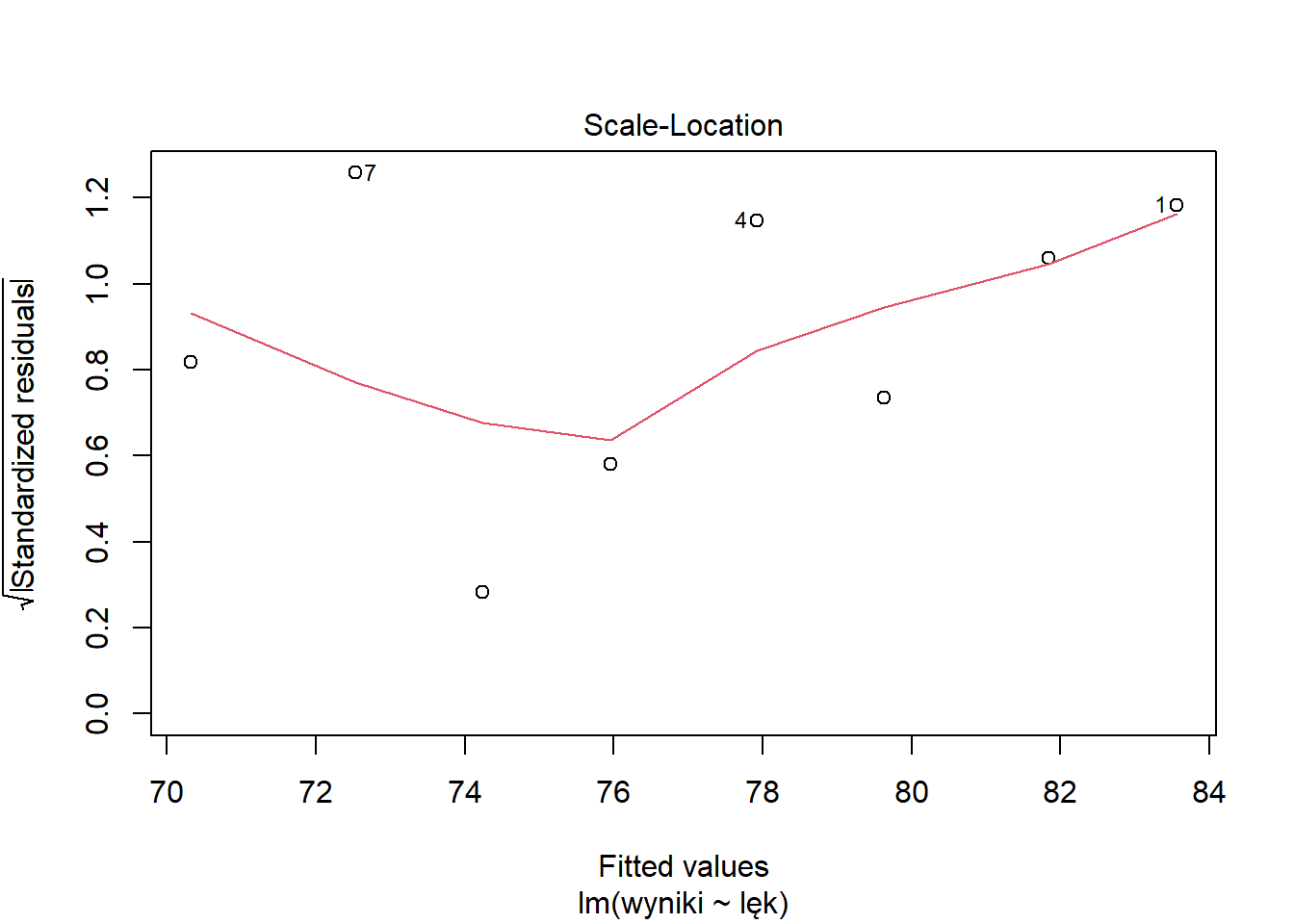
Krok 4: Analiza Reszt dla Najlepszego Modelu
Na podstawie wartości R-kwadrat, analiza reszt dla najlepiej dopasowanego modelu:
# Wykresy reszt dla najlepszego modelupar(mfrow =c(2, 2))plot(model_linearlog)
Krok 5: Interpretacja Najlepszego Modelu
Współczynniki modelu liniowo-logarytmicznego:
summary(model_linearlog)
Call:
lm(formula = GH ~ log_DM, data = data)
Residuals:
Min 1Q Median 3Q Max
-0.40702 -0.30207 -0.04907 0.22905 0.60549
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 19.0223 0.4079 46.64 0.0000000000494 ***
log_DM -2.0599 0.2232 -9.23 0.0000153880425 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.3712 on 8 degrees of freedom
Multiple R-squared: 0.9142, Adjusted R-squared: 0.9034
F-statistic: 85.19 on 1 and 8 DF, p-value: 0.00001539
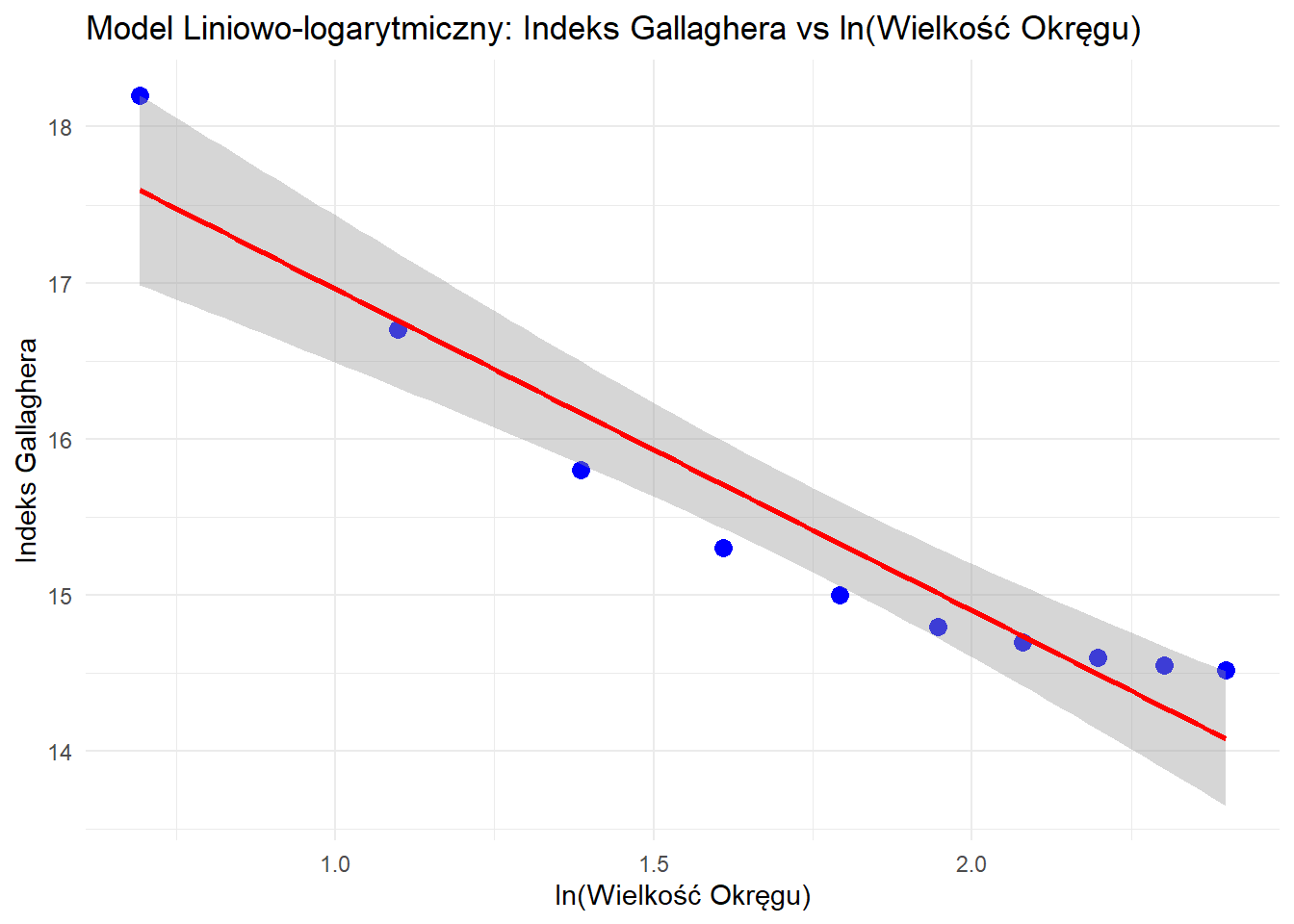
Interpretacja:
\hat{\beta_0} reprezentuje oczekiwany Indeks Gallaghera, gdy ln(DM) = 0 (czyli gdy DM = 1)
\hat{\beta_1} reprezentuje zmianę Indeksu Gallaghera związaną z jednostkowym wzrostem ln(DM)
Krok 6: Predykcje Modelu
# Tworzenie wykresu predykcji dla najlepszego modeluggplot(data, aes(x = log_DM, y = GH)) +geom_point(color ="blue", size =3) +geom_smooth(method ="lm", se =TRUE, color ="red") +labs(title ="Model Liniowo-logarytmiczny: Indeks Gallaghera vs ln(Wielkość Okręgu)",x ="ln(Wielkość Okręgu)",y ="Indeks Gallaghera" ) +theme_minimal()
`geom_smooth()` using formula = 'y ~ x'
Krok 7: Analiza Elastyczności
Dla modelu log-log współczynniki bezpośrednio reprezentują elastyczności. Obliczenie średniej elastyczności dla modelu liniowo-logarytmicznego:
Kowariancja mierzy, jak dwie zmienne zmieniają się wspólnie. Dodatnia kowariancja wskazuje, że gdy jedna zmienna rośnie, druga również ma tendencję do wzrostu.
Znajduje linię minimalizującą sumę kwadratów reszt
Produkuje nieobciążone estymatory o minimalnej wariancji (BLUE)
R-kwadrat (0.74) oznacza:
74% zmienności umiejętności jest wyjaśnione przez godziny ćwiczeń
Korelacja między przewidywanymi a rzeczywistymi odchyleniami wynosi \sqrt{0.74} = 0.86
SSR stanowi 74% SST; SSE stanowi 26% SST
Interpretacja Geometryczna:
Całkowita zmienność = odległość każdego punktu od średniej
Model uchwytuje 74% tych odległości przez linię regresji
Pozostałe 26% jest niewyjaśnione (reszty)
Implikacja Praktyczna:
Każda dodatkowa godzina ćwiczeń zwiększa oczekiwaną umiejętność o 1.2 punktu, a ten związek wyjaśnia większość (ale nie całość) obserwowanej zmienności!
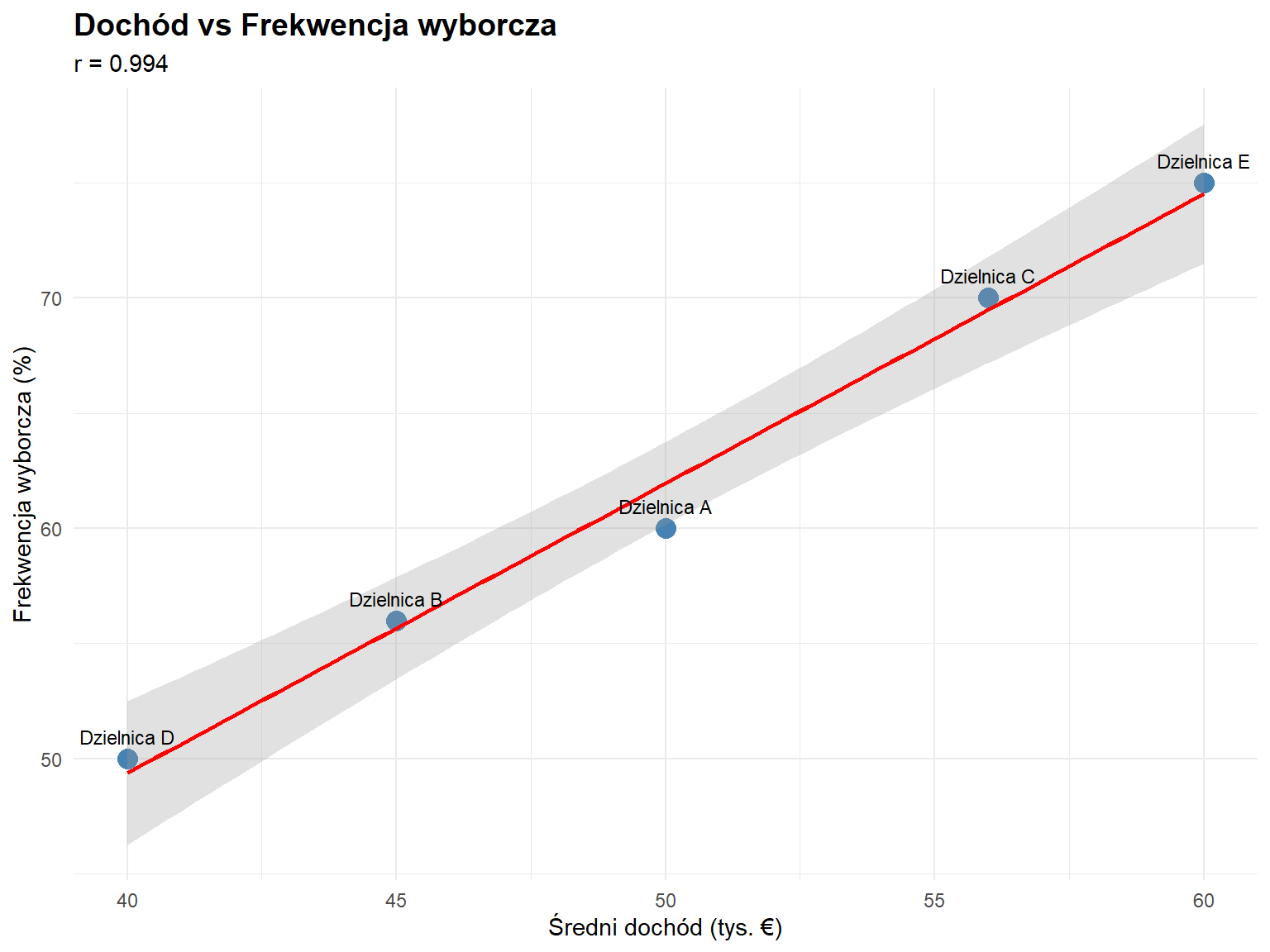
10.17 Przykład 1. Analiza związku między dobrobytem ekonomicznym a frekwencją wyborczą
Analiza związku między dobrobytem ekonomicznym a frekwencją wyborczą w dzielnicach średniej wielkości europejskiego miasta na podstawie danych z wyborów samorządowych.
Istnieje silna dodatnia korelacja (r = 0.994) między dochodem a frekwencją wyborczą
Model wyjaśnia 98.9% zmienności w danych
Dzielnice z wyższymi dochodami mają wyższą frekwencję wyborczą
Ważne ograniczenie:
⚠️ Mała próba (n=5) oznacza, że wyniki należy traktować ostrożnie i nie można ich generalizować na całą populację bez dodatkowych badań.
Praktyczne zastosowanie:
Wyniki sugerują, że działania mające na celu zwiększenie frekwencji wyborczej powinny szczególnie koncentrować się na dzielnicach o niższych dochodach.
Ograniczenia i zastrzeżenia:
⚠️ Krytyczne ograniczenia:
Bardzo mała próba (n=5) znacznie ogranicza możliwość generalizacji
Niska moc statystyczna - ryzyko błędów II rodzaju
Brak kontroli zmiennych zakłócających (wiek, wykształcenie, gęstość zaludnienia)
Możliwa korelacja pozorna - potrzebne dodatkowe zmienne kontrolne
Rekomendacje dla przyszłych badań:
Zwiększenie próby do wszystkich dzielnic miasta
Włączenie zmiennych demograficznych i socjoekonomicznych
Analiza danych longitudinalnych z kilku cykli wyborczych
10.18 Przykład 2. Związek Między Wielkością Okręgu a Dysproporcjonalnością Wyborczą (1)
Ta analiza bada związek między wielkością okręgu wyborczego (DM) a wskaźnikiem dysproporcjonalności Loosemore-Hanby (LH) w wyborach parlamentarnych w 6 krajach. Indeks Loosemore-Hanby mierzy dysproporcjonalność wyborczą, gdzie wyższe wartości wskazują na większą dysproporcjonalność między głosami a mandatami.
Dane
Warning: package 'knitr' was built under R version 4.4.3
Wielkość Okręgu i Indeks LH według Kraju
Country
DM
LH
A
3
15.50
B
4
14.25
C
5
13.50
D
6
13.50
E
7
13.00
F
8
12.75
Krok 1: Obliczenie wariancji i odchylenia standardowego dla DM i LH
Ujemna kowariancja wskazuje na odwrotną zależność: gdy wielkość okręgu wzrasta, indeks dysproporcjonalności LH ma tendencję do spadku.
Krok 3: Obliczenie współczynnika korelacji liniowej Pearsona między DM i LH
Współczynnik korelacji Pearsona obliczany jest przy użyciu formuły:
r = \frac{Cov(DM, LH)}{\sigma_{DM} \cdot \sigma_{LH}}
Mamy już obliczone:
Cov(DM, LH) = -1.75
\sigma_{DM} = 1.871
\sigma_{LH} = 1
r = \frac{-1.75}{1.871 \cdot 1} = \frac{-1.75}{1.871} = -0.935
Współczynnik korelacji Pearsona: -0.935
Interpretacja:
Współczynnik korelacji -0.935 wskazuje:
Kierunek: Znak ujemny pokazuje odwrotną zależność między wielkością okręgu a indeksem LH.
Siła: Wartość bezwzględna 0.935 wskazuje na bardzo silną korelację (blisko -1).
Interpretacja praktyczna: Ponieważ wyższe wartości indeksu LH wskazują na większą dysproporcjonalność, ta silna ujemna korelacja sugeruje, że gdy wielkość okręgu wzrasta, dysproporcjonalność wyborcza ma tendencję do znacznego spadku. Innymi słowy, systemy wyborcze z większymi okręgami (więcej przedstawicieli wybieranych z jednego okręgu) zwykle dają bardziej proporcjonalne wyniki (niższa dysproporcjonalność).
Odkrycie to jest zgodne z teorią nauk politycznych, która sugeruje, że większe okręgi zapewniają więcej możliwości mniejszym partiom, aby uzyskać reprezentację, co prowadzi do wyników wyborczych, które lepiej odzwierciedlają rozkład głosów między partiami.
Krok 4: Skonstruowanie modelu regresji liniowej prostej i obliczenie R-kwadrat
Równanie regresji: Dla każdego wzrostu jednostkowego wielkości okręgu, indeks dysproporcjonalności LH jest oczekiwany spadek o 0.5 jednostki. Wyraz wolny (16.5) reprezentuje oczekiwany indeks LH, gdy wielkość okręgu wynosi zero (choć nie ma to praktycznego znaczenia, ponieważ wielkość okręgu nie może wynosić zero).
R-kwadrat: 0.875 wskazuje, że około 87.5% wariancji w dysproporcjonalności wyborczej (indeks LH) może być wyjaśnione przez wielkość okręgu. Jest to wysoka wartość, sugerująca, że wielkość okręgu jest rzeczywiście silnym predyktorem dysproporcjonalności wyborczej.
RMSE i MAE: Niskie wartości RMSE (0.323) i MAE (0.25) wskazują, że model dobrze dopasowuje się do danych, z małymi błędami predykcji.
Implikacje polityczne: Odkrycia sugerują, że zwiększanie wielkości okręgu mogłoby być skuteczną strategią reformy wyborczej dla krajów dążących do zmniejszenia dysproporcjonalności między głosami a mandatami. Jednak korzyści marginalne wydają się zmniejszać wraz ze wzrostem wielkości okręgu, jak widać w wzorcu danych.
10.19 Przykład 3. Analiza związku między wielkością okręgu a wskaźnikiem dysproporcjonalności wyborczej (2)
Ta analiza bada związek między wielkością okręgu (DM) a wskaźnikiem dysproporcjonalności Loosemore-Hanby (LH) w wyborach parlamentarnych w 6 krajach. Wskaźnik Loosemore-Hanby mierzy dysproporcjonalność wyborczą, przy czym wyższe wartości wskazują na większą dysproporcjonalność między głosami a mandatami.
Dane
Wielkość okręgu i wskaźnik LH według kraju
Kraj
DM
LH
A
4
12
B
10
8
C
3
15
D
8
10
E
7
6
F
4
13
Krok 1: Obliczenie wariancji i odchylenia standardowego dla DM i LH
Ujemna kowariancja wskazuje na odwrotną zależność: wraz ze wzrostem wielkości okręgu wskaźnik dysproporcjonalności LH ma tendencję do spadku.
Krok 3: Obliczenie współczynnika korelacji liniowej Pearsona między DM a LH
Współczynnik korelacji Pearsona oblicza się przy użyciu wzoru:
r = \frac{Cov(DM, LH)}{s_{DM} \cdot s_{LH}}
Mamy już obliczone:
Cov(DM, LH) = -7.4
s_{DM} = 2.757
s_{LH} = 3.327
r = \frac{-7.4}{2.757 \cdot 3.327} = \frac{-7.4}{9.172} = -0.807
Współczynnik korelacji Pearsona: -0.807
Interpretacja:
Współczynnik korelacji -0.807 wskazuje:
Kierunek: Ujemny znak pokazuje odwrotną zależność między wielkością okręgu a wskaźnikiem LH.
Siła: Wartość bezwzględna 0.807 wskazuje na silną korelację (blisko -1).
Interpretacja praktyczna: Ponieważ wyższe wartości wskaźnika LH wskazują na większą dysproporcjonalność, ta silna ujemna korelacja sugeruje, że wraz ze wzrostem wielkości okręgu, dysproporcjonalność wyborcza ma tendencję do znacznego spadku. Innymi słowy, systemy wyborcze z większymi okręgami wyborczymi (więcej przedstawicieli wybieranych w okręgu) mają tendencję do generowania bardziej proporcjonalnych wyników (mniejsza dysproporcjonalność).
Ustalenie to jest zgodne z teorią nauk politycznych, która sugeruje, że większe okręgi wyborcze zapewniają mniejszym partiom więcej możliwości uzyskania reprezentacji, co prowadzi do wyników wyborczych, które lepiej odzwierciedlają rozkład głosów między partiami.
Krok 4: Skonstruowanie prostego modelu regresji liniowej i obliczenie R-kwadrat
Korekta Bessela (dzielenie przez n-1 zamiast n) stosuje się do estymacji wariancji próby, ale nie jest standardowo stosowana przy obliczaniu RMSE, gdyż RMSE jest miarą błędu predykcji, a nie estymatorem parametru populacji.
Obliczanie MAE (Średni błąd bezwzględny)
MAE oblicza się przy użyciu wzoru:
MAE = \frac{1}{n}\sum_{i=1}^{n}|y_i - \hat{y}_i|
Kraj
LH (y_i)
Przewidywane LH (\hat{y}_i)
|y_i - \hat{y}_i|
A
12
12.615
|12 - 12.615| = 0.615
B
8
6.771
|8 - 6.771| = 1.229
C
15
13.589
|15 - 13.589| = 1.411
D
10
8.719
|10 - 8.719| = 1.281
E
6
9.693
|6 - 9.693| = 3.693
F
13
12.615
|13 - 12.615| = 0.385
Suma
8.614
MAE = \frac{8.614}{6} = 1.436
Model regresji: LH = 16.511 - 0.974 \cdot DM
R-kwadrat: 0.651
RMSE: 1.794
MAE: 1.436
Interpretacja:
Równanie regresji: Dla każdego jednostkowego wzrostu wielkości okręgu, wskaźnik dysproporcjonalności LH zmniejsza się o 0.974 jednostki. Wyraz wolny (16.511) reprezentuje oczekiwany wskaźnik LH, gdy wielkość okręgu wynosi zero (choć nie ma to praktycznego znaczenia, ponieważ wielkość okręgu nie może wynosić zero).
R-kwadrat: 0.651 wskazuje, że około 65.1% wariancji dysproporcjonalności wyborczej (wskaźnik LH) może być wyjaśnione przez wielkość okręgu. Jest to dość wysoka wartość, sugerująca, że wielkość okręgu jest rzeczywiście silnym predyktorem dysproporcjonalności wyborczej, choć mniejszym niż w poprzednim zestawie danych.
RMSE: Wartość 1.794 informuje nas o przeciętnym błędzie prognozy modelu. Jest to miara dokładności przewidywań modelu wyrażona w jednostkach zmiennej zależnej (LH).
MAE: Wartość 1.436 informuje nas o przeciętnym bezwzględnym błędzie prognozy modelu. W porównaniu z RMSE, MAE jest mniej czuły na wartości odstające, co potwierdza, że niektóre obserwacje (np. dla kraju E) mają stosunkowo duży błąd predykcji.
Implikacje polityczne: Wyniki sugerują, że zwiększenie wielkości okręgu mogłoby być skuteczną strategią reform wyborczych dla krajów starających się zmniejszyć dysproporcjonalność między głosami a mandatami. Jednakże, korzyści marginalne wydają się zmniejszać wraz ze wzrostem wielkości okręgu, jak widać we wzorcu danych.
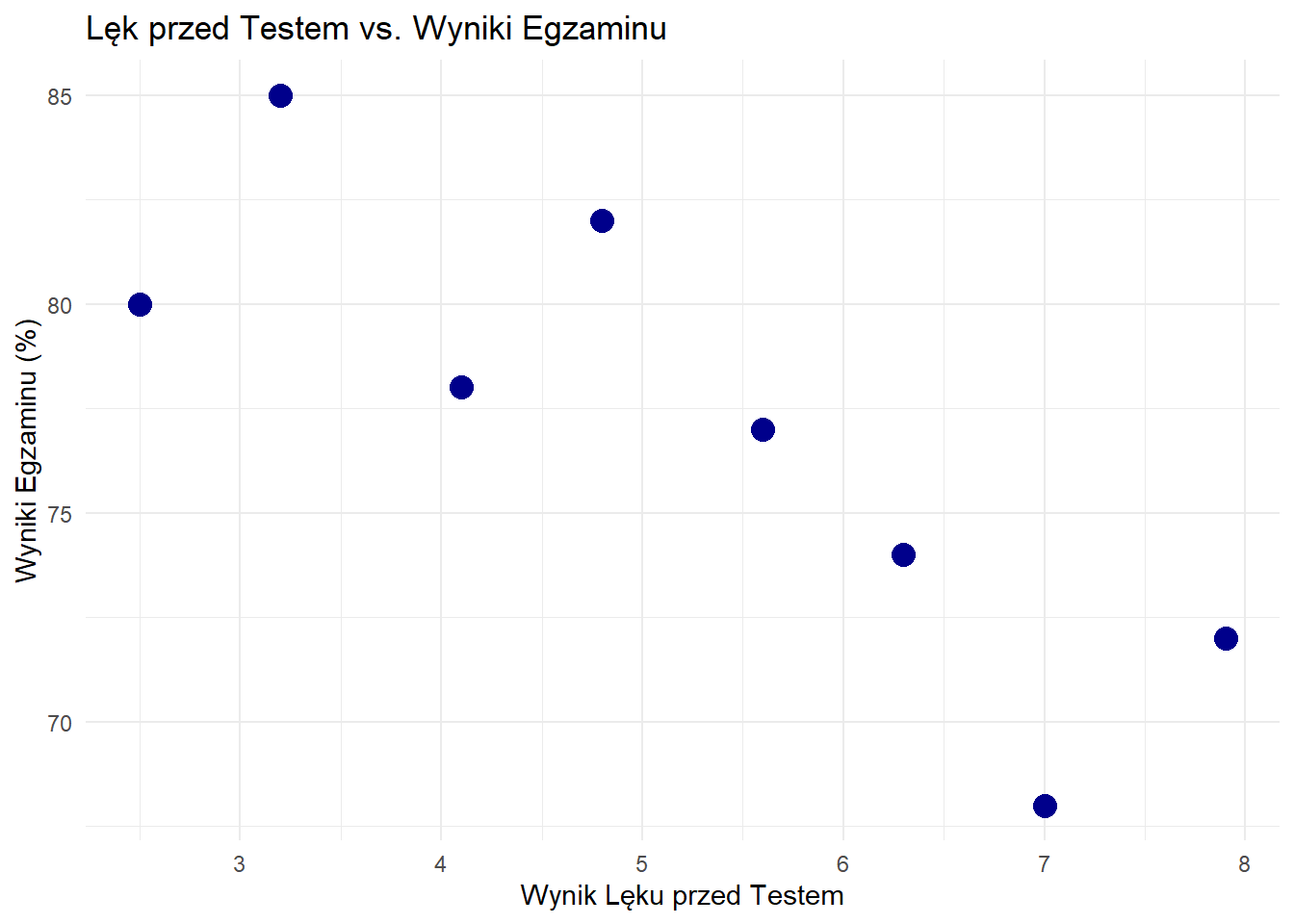
10.20 Przykład 4. Lęk vs. Wyniki Egzaminu: Analiza Korelacji i Regresji
W tym tutorialu zbadamy związek między poziomem lęku przed egzaminem a wynikami egzaminacyjnymi wśród studentów uniwersytetu. Badania sugerują, że podczas gdy niewielka ilość lęku może być motywująca, nadmierny lęk zazwyczaj pogarsza wyniki poprzez zmniejszoną koncentrację, zakłócenia pamięci roboczej i objawy fizyczne (Yerkes-Dodson law). Przeanalizujemy dane od 8 studentów, aby zrozumieć ten związek matematycznie.
Prezentacja Danych
Zbiór Danych
Zebraliśmy dane od 8 studentów, mierząc:
X: Wynik lęku przed testem (skala 1-10, gdzie 1 = bardzo niski, 10 = bardzo wysoki)
Y: Wyniki egzaminu (wynik procentowy)
# Nasze danelęk <-c(2.5, 3.2, 4.1, 4.8, 5.6, 6.3, 7.0, 7.9) # Wyniki lękuwyniki <-c(80, 85, 78, 82, 77, 74, 68, 72) # Wyniki egzaminu (%)# Stworzenie ramki danych dla łatwego przeglądudane <-data.frame(Student =1:8, Lęk = lęk,Wyniki = wyniki)print(dane)
Kiedy obserwujemy związek między dwiema zmiennymi, chcemy znaleźć model matematyczny, który:
Opisuje związek
Pozwala nam dokonywać prognoz
Kwantyfikuje siłę związku
Najprostszym modelem jest linia prosta: Y = \beta_0 + \beta_1 X + \epsilon
Gdzie:
Y to zmienna wynikowa (wyniki)
X to zmienna predykcyjna (lęk)
\beta_0 to punkt przecięcia (wyniki gdy lęk = 0)
\beta_1 to nachylenie (zmiana wyników na jednostkę zmiany lęku)
\epsilon to składnik błędu (niewyjaśniona zmienność)
Idea Sumy Kwadratów Błędów (SSE)
Wyobraź sobie próbę narysowania linii przez nasze punkty danych. Jest nieskończenie wiele linii, które moglibyśmy narysować! Niektóre przeszłyby przez środek punktów, inne mogłyby być za wysokie lub za niskie, za strome lub za płaskie. Potrzebujemy systematycznego sposobu określenia, która linia jest “najlepsza”.
Czym są Błędy (Reszty)?
Dla każdej linii, którą narysujemy, każdy punkt danych będzie miał błąd lub resztę - pionową odległość od punktu do linii. To reprezentuje, jak “błędna” jest nasza prognoza dla tego punktu.
Błąd dodatni: Rzeczywista wartość jest powyżej przewidywanej wartości (niedoszacowaliśmy)
Błąd ujemny: Rzeczywista wartość jest poniżej przewidywanej wartości (przeszacowaliśmy)
Dlaczego Podnosimy Błędy do Kwadratu?
Proste dodawanie błędów nie zadziała, ponieważ błędy dodatnie i ujemne się znoszą. Moglibyśmy użyć wartości bezwzględnych, ale podnoszenie do kwadratu ma kilka zalet:
Wygoda matematyczna: Funkcje kwadratowe są różniczkowalne, co ułatwia znalezienie minimum za pomocą rachunku różniczkowego
Penalizuje większe błędy bardziej: Kilka dużych błędów jest gorsze niż wiele małych błędów
Tworzy gładką, miskowatą funkcję: To gwarantuje unikalne minimum
“Najlepsza” linia to ta, która minimalizuje SSE. Używając rachunku różniczkowego (biorąc pochodne względem \beta_0 i \beta_1 i przyrównując je do zera), otrzymujemy wzory MNK.
Estymatory MNK
Metoda Najmniejszych Kwadratów (MNK) znajduje wartości \beta_0 i \beta_1, które minimalizują SSE:
Za każdy wzrost lęku o 1 punkt, wyniki spadają o 2,45%
Wykres Modelu
library(ggplot2)# Stworzenie kompleksowego wykresuggplot(data.frame(lęk, wyniki), aes(x = lęk, y = wyniki)) +geom_point(size =4, color ="darkblue") +geom_smooth(method ="lm", se =FALSE, color ="red", linewidth =1) +geom_text(aes(label =paste0("(", round(lęk, 1), ", ", wyniki, ")")),vjust =-1, size =3) +annotate("text", x =3, y =70, label =paste0("ŷ = ", round(coef(model)[1], 2), " - ", abs(round(coef(model)[2], 2)), "x"),size =5, color ="red") +labs(title ="Linia Regresji: Wyniki vs. Lęk",subtitle ="Wyższy lęk jest związany z niższymi wynikami egzaminu",x ="Wynik Lęku przed Testem",y ="Wyniki Egzaminu (%)" ) +theme_minimal() +scale_x_continuous(breaks =seq(2, 8, 1)) +scale_y_continuous(breaks =seq(65, 90, 5))
`geom_smooth()` using formula = 'y ~ x'
Ocena Modelu
Dekompozycja Wariancji
Całkowita zmienność w Y może być rozłożona na dwie części:
SST = SSE + SSR
Gdzie:
SST (Sum of Squares Total): Całkowita zmienność w Y
SSE (Sum of Squared Errors): Niewyjaśniona zmienność
SSR (Sum of Squares Regression): Wyjaśniona zmienność
Tip
Wyobraź sobie, że chcesz zrozumieć, dlaczego pensje w firmie się różnią. Jedni zarabiają 40 000, inni 80 000, a jeszcze inni 120 000. Mamy więc zmienność wynagrodzeń — nie są takie same.
Całkowita zmienność (SST)
To pytanie: „Jak bardzo wszystkie pensje są rozproszone wokół średniej pensji?” Jeśli średnia to 70 000, to SST mierzy, o ile każda pensja różni się od 70 000, podnosi te różnice do kwadratu (żeby były dodatnie) i sumuje. To całkowita ilość zmienności, którą próbujemy wyjaśnić.
Zmienność wyjaśniona (SSR)
Załóżmy, że budujemy model przewidujący pensję na podstawie lat doświadczenia. Model może mówić:
2 lata doświadczenia → przewiduje 50 000
5 lat doświadczenia → przewiduje 70 000
10 lat doświadczenia → przewiduje 100 000
SSR mierzy, jak bardzo te przewidywania różnią się od średniej. To ta część zmienności, którą model „wyjaśnia” relacją z doświadczeniem. Innymi słowy: „tę część różnic w pensjach da się przypisać różnym poziomom doświadczenia”.
Zmienność niewyjaśniona (SSE)
To to, co zostaje — część, której model nie tłumaczy. Może być tak, że dwie osoby mają po 5 lat doświadczenia, ale jedna zarabia 65 000, a druga 75 000. Model obu przewidział 70 000. Te różnice względem przewidywań (błędy) reprezentują zmienność wynikającą z innych czynników — np. edukacja, wyniki pracy, umiejętności negocjacyjne albo po prostu losowość.
10.21 Kluczowa intuicja
Piękne jest to, że te trzy wielkości zawsze spełniają zależność: Całkowita zmienność = Zmienność wyjaśniona + Zmienność niewyjaśniona czyli SST = SSR + SSE.
Możesz myśleć o tym jak o „wykresie kołowym powodów, dlaczego pensje się różnią”:
Jeden kawałek to „różnice wyjaśnione doświadczeniem” (SSR),
Drugi kawałek to „różnice z innych powodów” (SSE),
Razem dają całość (SST).
10.22 Dlaczego to ważne
To rozbicie pozwala policzyć współczynnik determinacjiR^2:
Jeśli R^2 = 0{,}70, to model wyjaśnia 70% tego, dlaczego wartościY (tu: pensje) różnią się między sobą. Pozostałe 30% to czynniki nieuwzględnione lub szum losowy.
Pomyśl o tym jak o rozwiązywaniu zagadki: SST to cała zagadka do rozwiązania, SSR to część już rozwiązana, a SSE to to, co wciąż pozostaje do wyjaśnienia!
Mówiąc prościej: Przedział ufności daje nam zakres prawdopodobnych wartości dla naszego prawdziwego nachylenia. Gdybyśmy powtórzyli to badanie wiele razy, 95% obliczonych przez nas przedziałów zawierałoby prawdziwą wartość nachylenia.
Wzór używa wartości krytycznej (około 2,45 dla 6 stopni swobody):
Interpretacja: Jesteśmy w 95% pewni, że prawdziwa zmiana wyników na jednostkę zmiany lęku mieści się między -4,10% a -0,81%.
Istotność Statystyczna
Aby sprawdzić, czy związek jest statystycznie istotny (tj. nie jest przypadkowy), obliczamy statystykę t:
t = \frac{\hat{\beta_1}}{BE(\hat{\beta_1})} = \frac{-2,451}{0,671} = -3,653
Mówiąc prościej: Ta wartość t mówi nam, o ile błędów standardowych nasze nachylenie odbiega od zera. Wartość bezwzględna 3,65 jest dość duża (zazwyczaj wartości przekraczające ±2,45 są uważane za istotne dla naszej wielkości próby), dostarczając silnego dowodu na rzeczywisty ujemny związek między lękiem a wynikami.
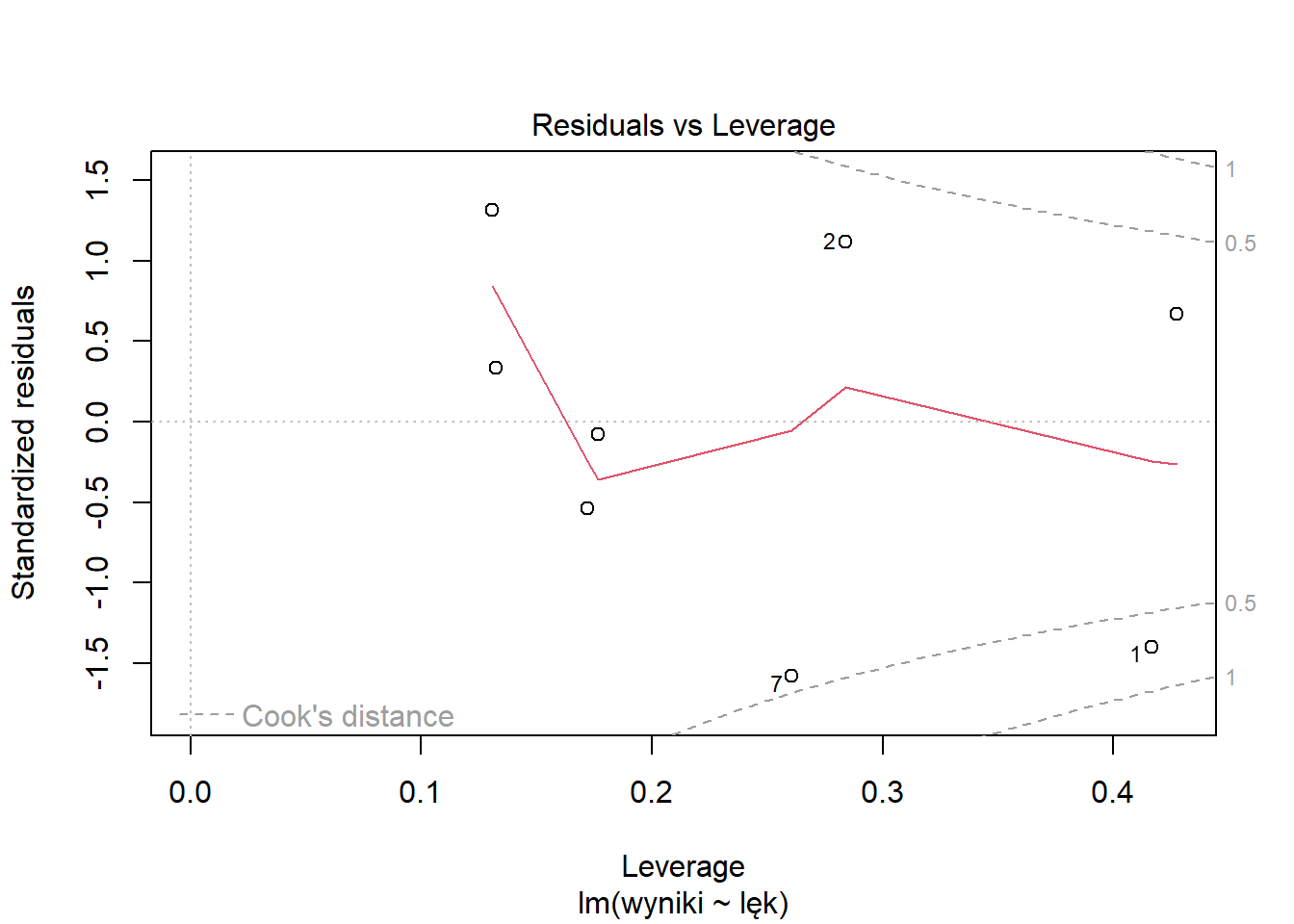
# Weryfikacja obliczeń z Rsummary(model)
Call:
lm(formula = wyniki ~ lęk)
Residuals:
Min 1Q Median 3Q Max
-4.526 -2.116 0.400 2.050 4.081
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 89.6872 3.6682 24.450 0.000000308 ***
lęk -2.4516 0.6714 -3.652 0.0107 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.327 on 6 degrees of freedom
Multiple R-squared: 0.6897, Adjusted R-squared: 0.6379
F-statistic: 13.33 on 1 and 6 DF, p-value: 0.01069